Supervised Learning with sckit-learn¶
- William Surles
- 2017-11-27
- Datacamp class
- https://www.datacamp.com/courses/supervised-learning-with-scikit-learn
Whats Covered¶
Classification
- Supervised learning
- Exploratory data analysis
- The classification challenge
- Measuring model performance
Regression
- Introduction to regression
- The basics of linear regression
- Cross-validation
- Regularized regression
Fine-tuning your model
- How good is your model?
- Logistic regression and the ROC curve
- Area under the ROC curve
- Hyperparameter tuning
- Hold-out set for final evaluation
Preprocessing and pipelines
- Preprocessing data
- Handling missing data
- Centering and scaling
- Final thoughts
Additonal Resources¶
Libraries and Data¶
from sklearn import datasets
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import seaborn as sns
Classification¶
Supervised learning¶
What is machine learning¶
- the art and science of:
- Giving computers the ability to learn to make decisions from data
- ... without being explicitly programmed!
- Examples:
- Learning to predict whether an email is spam or not
- Clustering wikipedia entries into different categories
- Supervised learning: Uses labeled data
- Unsupervised learning: uses unlabeled data
- Reinfocemnet learning: uses an environment with punishments and rewards to train future behavior
Unsupervised Learning¶
- Uncovering hidden patterns from unlabeled data
- Example:
- Grouping customers into distinct categories (Clustering)
Reinforcement learning¶
- Software agents interact with an environment
- Learn how to optimize their behavior
- given a system fo rewards and punishments
- Draws inspiration from behavioral pyschology
- Applications
- Economics
- Genetics
- Game playing
- AlphaGo: First computer to defeat the world champion in Go
Supervised Learning¶
- Predictor variables/features and a target variable
- Aim: Predict the target variable, given the predictor variables
- Classification: Target variable consists of categories
- Regression: Target variable is continuous
Naming Conventions
- Features = predictor variables = independent variables
- Target variable = dependent variable = response variable
In practice
- Automate time-consuming or expensive maual tasks
- Example: Doctor's diagnosis
- Make predictions about the future
- Example: Will a customer click on an ad or not?
- Need Labeled data
- Historical data with labels
- Experiments to get labeled data
- Crowd-sourcing labeled data
In Python
- We wil use scikit-learn/sklearn
- Integrates well with the SciPy stack
- Other libaries
- TensorFlow
- keras
Which of these is a classification problem?¶
- Classification (Supervised)
- Using labeled financial data to predict whether the value of a stock will go up or go down next week.
- Regression (Supervised)
- Using labeled housing price data to predict the price of a new house based on various features.
- Using labeled financial data to predict what the value of a stock will be next week.
- Clustering (Unsupervised)
- Using unlabeled data to cluster the students of an online education company into different categories based on their learning styles.
Exploratory data analysis¶
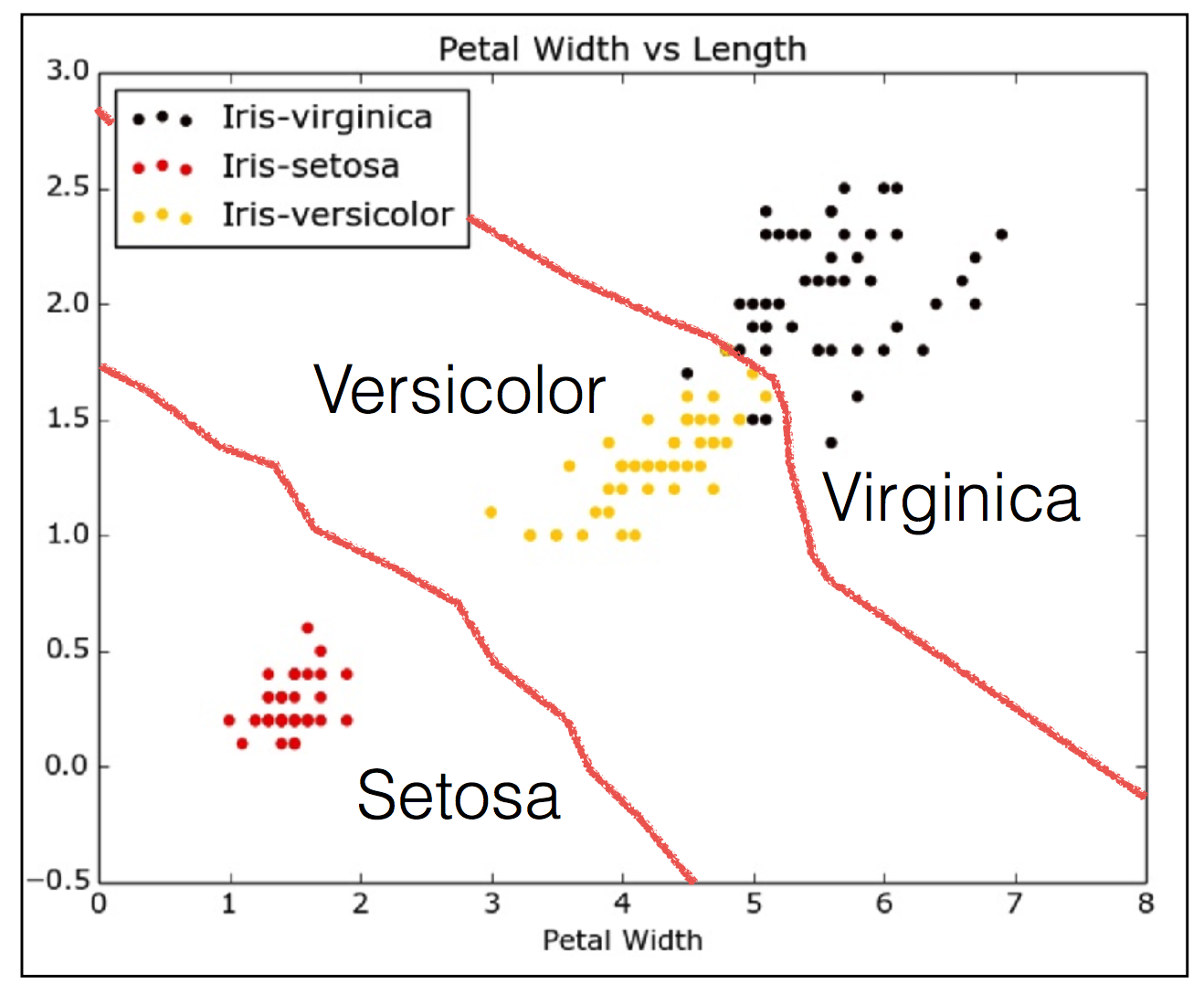
The Iris dataset
- Features:
- Petal length
- petal width
- Sepal length
- Sepal width
- Target variable: Species
- Versicolor
- Verginica
- Setosa
The Iris dataset in scikit-learn¶
- This data comes in a 'Bunch' which is kind of like a dictionary.
iris = datasets.load_iris()
type(iris)
- Here are the keys. We can see that the data and the target are separate.
- Also the target is integers and the corresponding names are held in target_names
- There is also a description which is nice
- But the target_names and feature_names are separate
- We will need to combine these as we do EDA on the data
iris.keys()
iris.data[:6,:]
iris.target
iris.feature_names
iris.target_names
iris.DESCR
EDA¶
X = iris.data
y = iris.target
df = pd.DataFrame(X, columns = iris.feature_names)
df.head()
_ = pd.plotting.scatter_matrix(
df,
c = y,
figsize = [14,14],
s = 100,
marker = 'D')
plt.show()

Numerical EDA¶
- In this chapter, we'll be working with a dataset obtained from the UCI Machine Learning Repository consisting of votes made by US House of Representatives Congressmen.
- Our goal will be to predict their party affiliation ('Democrat' or 'Republican') based on how they voted on certain key issues.
- The data has been preproceesed
- We will practice the processing techniques on this data in chp 4
- Before thinking about what supervised learning models we can apply to this, we will perform EDA in order to understand the structure of the data.
%run data.py
vote_clean = pd.DataFrame(data = vote_clean_list, columns = vote_clean_columns)
vote_clean.head()
vote_clean.head()
vote_clean.info()
vote_clean.describe()
Observations¶
- The dataframe has a total of 435 rows and 17 columns
- Except for
party, all of the columns are of typeint64. - The first two rows of the dataframe consist of votes made by republicans, and then next three rows consist of votes made by democrats
- There are 16 predictor variables, or features, in this dataframe
- And one target variable,
party.
- And one target variable,
Visual EDA¶
- In the video we used the
scatter_matrix()but here we have all binary data so acountplot()(fromseaborn) is more appropriate.- We will look at the
countplot()for a few variables - We will make the colors match the party affiliations
- We will look at the
plt.figure(figsize=(18,10))
sns.countplot(x='education', hue='party', data=vote_clean, palette='RdBu')
plt.xticks([0,1], ['No', 'Yes'])
plt.show()

plt.figure(figsize=(18,10))
sns.countplot(x='satellite', hue='party', data=vote_clean, palette='RdBu')
plt.xticks([0,1], ['No', 'Yes'])
plt.show()

plt.figure(figsize=(18,10))
sns.countplot(x='missile', hue='party', data=vote_clean, palette='RdBu')
plt.xticks([0,1], ['No', 'Yes'])
plt.show()

Observations¶
- Repblicans wer much more in favor of education and more against the satelite and missile issue.
- We don't know what the actual question was, but we can certainly see how the parties vote differently.
- This is the kind of information that our machine learning model will seek to learn when we try to predict party affiliation solely based on voting behavior.
- An expert in U.S politics may be able to predict this without machine learning, but probably not instantaneously - and certainly not if we are dealing with hundreds of samples!
The classification challenge¶
k-Nearest Neighbors¶
- Basic idea: Predict the label of a data point by
- Looking at the 'k' closest labeled data points
- Taking a majority vote
Oversimple example¶
- If it were knn 3 than the center dot would be red since its 3 nearest neighbors are 2 red and 1 green
- If it were knn 5 than it would be green. 3 green and 2 red
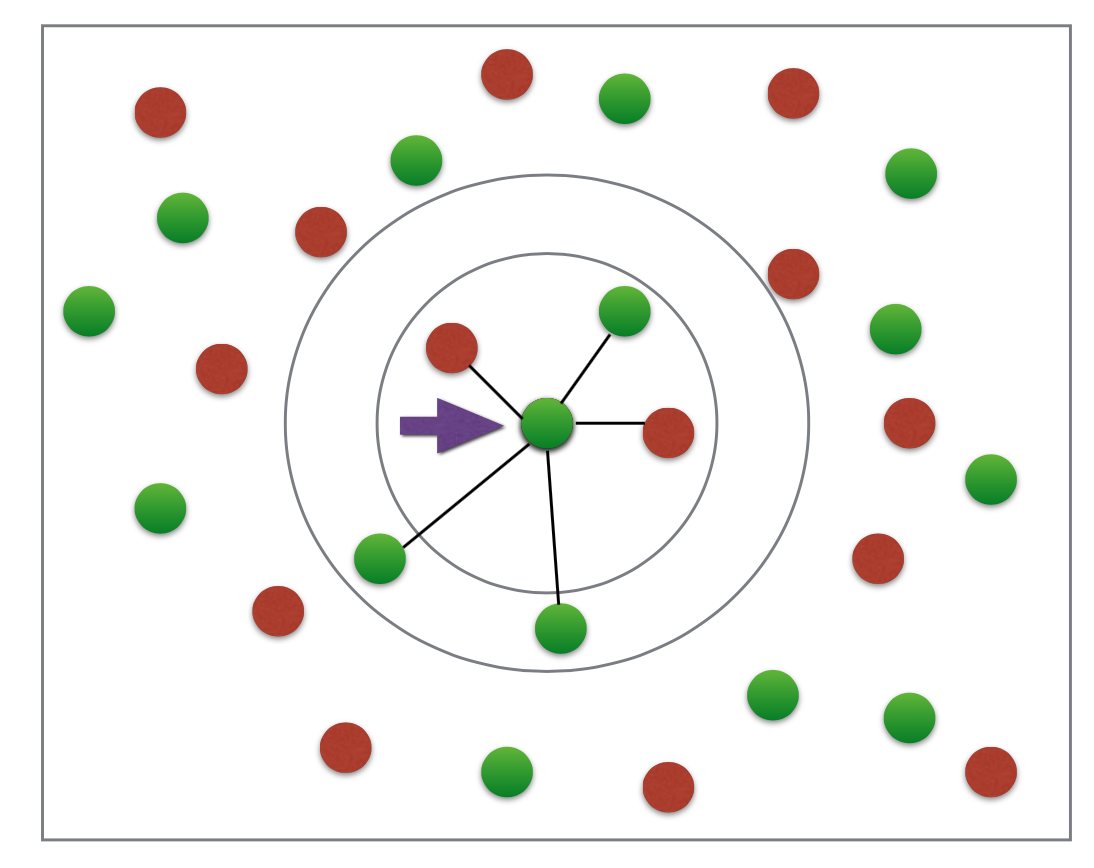
k-NN: Intuition¶
- At some point things converge and you have your groups
Scikit-learn fit and predict¶
- All machine learning models implemented as python classes
- They implement the algorithms for learning and predicting
- Store the information learned from the data
- Training a model on the data = 'fitting' a model to the data
.fit()method
- To predict the labels of new data:
.predict()method
Using scikit-learn to fit a classifier¶
- The scikit-learn api requires:
- data as a numpy array or pandas data frame
- the feature take on continuous values (like the price of a house, as opposed to a category, big or small house)
- no missing values in the data
- the features are in an array where each column is a feature and each row is an observation
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 6)
knn.fit(iris['data'], iris['target'])
iris['data'].shape
iris['target'].shape
Prediciting on unlabeled data¶
X_new = iris['data'][[0,10,100,149],:] + np.random.random((4, 4))
X_new
prediction = knn.predict(X_new)
X_new.shape
print('Prediction {}'. format(prediction))
- the first two are setosa and the second two are virginica
k-Nearest Neighbors: Fit¶
- Note the use of .drop() to drop the target variable 'party' from the feature array X as well as the use of the .values attribute to ensure X and y are NumPy arrays.
- Without using .values, X and y are a DataFrame and Series respectively;
- the scikit-learn API will accept them in this form also as long as they are of the right shape.
# Import KNeighborsClassifier from sklearn.neighbors
from sklearn.neighbors import KNeighborsClassifier
# Create arrays for the features and the response variable
y = vote_clean['party'].values
X = vote_clean.drop('party', axis=1).values
# Create a k-NN classifier with 6 neighbors
knn = KNeighborsClassifier(n_neighbors = 6)
# Fit the classifier to the data
knn.fit(X, y)
k-Nearest Neighbors: Predict¶
Having fit a k-NN classifier, you can now use it to predict the label of a new data point.
- However, there is no unlabeled data available since all of it was used to fit the model!
- You can still use the .predict() method on the X that was used to fit the model, but it is not a good indicator of the model's ability to generalize to new, unseen data.
In the next video we will cover splitting our data to fix this issues
- For now, a random unlabeled data point has been generated and is available to you as X_new.
- You will use your classifier to predict the label for this new data point, as well as on the training data X that the model has already seen.
- Using .predict() on X_new will generate 1 prediction, while using it on X will generate 435 predictions: 1 for each sample.
# Import KNeighborsClassifier from sklearn.neighbors
from sklearn.neighbors import KNeighborsClassifier
# Create arrays for the features and the response variable
y = vote_clean['party'].values
X = vote_clean.drop('party', axis = 1).values
# Create a k-NN classifier with 6 neighbors: knn
knn = KNeighborsClassifier(n_neighbors = 6)
# Fit the classifier to the data
knn.fit(X, y)
# Predict the labels for the training data X
y_pred = knn.predict(X)
print(y_pred[0:10])
# Predict and print the label for the new data point X_new
X_new = np.array([[0.72251225, 0.61952487, 0.25539929, 0.34978056, 0.04279606,
0.64407096, 0.74224677, 0.26632645, 0.90179262, 0.73532079,
0.96163873, 0.98119655, 0.79379732, 0.29022046, 0.44359749,
0.95018481]])
new_prediction = knn.predict(X_new)
print("Prediction: {}".format(new_prediction))
Measuring model performance¶
- In classification, accuracy is a commonly used metric
- Accuracy = Fraction of correct predictions
- Which data should be used to compute accuracy?
- How well will the model perform on new data?
- Could compute accuracy on data used to fit classifier...
- Not indicative of ability to generalize
- Split data into Training and test set
- Fit/train the classifier on the training set
- make predictions on test set
- Compare predictions with the known labels
Train/test split¶
test_sizeis the proportion of data that will be in the test setrandom_statesets a seed for the random number generator so later you can reporoduce you results laterstratifyensures that our data is split so it has similar ratios of target labels in both test and train as in the original data
from sklearn.model_selection import train_test_split
X = iris['data']
y = iris['target']
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 21,
stratify = y)
- Now we just train on the train data
- And test on the test data
- then we can score by comaring our y predictions to the actual y test data
knn = KNeighborsClassifier(n_neighbors=8)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print("Test set predictions:\n{}".format(y_pred))
knn.score(X_test, y_test)
Model complexity¶
- If we use very few neighbors we will get a more jagged decision boundary
- This will over fit data so that new data is not predictied as well
- Many neighbors will lead to a very smooth decision boundary.
- this may underfit the data so our model cannnot describe the data as accurately as needed
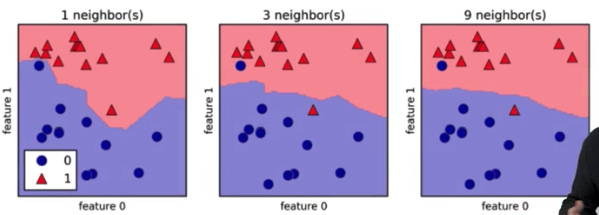
Model complexity and over/underfitting¶
- Here we can see that if our model is too simple (as in very large n) it does not do well on the training or test data.
- If we just set the neighbors to 1 you will have a very complex model that fits the training data very tightly, but when applying that model to the test data it will be low acuracy becuase its over fit on the training data.
- We want to find the sweet spot in the middle where we get the highes accuracy on new data.
- This will probably never be as good as any of the models fit to the training data but the point is to predict new data so thats how it is.
The digits recognition dataset¶
- In the following exercises, you'll be working with the MNIST digits recognition dataset, which has 10 classes, the digits 0 through 9!
- A reduced version of the MNIST dataset is one of scikit-learn's included datasets, and that is the one we will use in this exercise.
- Each sample in this scikit-learn dataset is an 8x8 image representing a handwritten digit.
- Each pixel is represented by an integer in the range 0 to 16, indicating varying levels of black.
- Helpfully for the MNIST dataset, scikit-learn provides an 'images' key in addition to the 'data' and 'target' keys - Because it is a 2D array of the images corresponding to each sample, this 'images' key is useful for visualizing the images
# Import necessary modules
from sklearn import datasets
import matplotlib.pyplot as plt
# Load the digits dataset: digits
digits = datasets.load_digits()
# Print the keys and DESCR of the dataset
print(digits.keys())
print(digits.DESCR)
# Print the shape of the images and data keys
print(digits.images.shape)
print(digits.data.shape)
# Display digit 1010
plt.imshow(digits.images[1010], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()

Train/Test Split + Fit/Predict/Accuracy¶
# Import necessary modules
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# Create feature and target arrays
X = digits.data
y = digits.target
# Split into training and test set
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.2,
random_state = 42,
stratify = y)
# Create a k-NN classifier with 7 neighbors: knn
knn = KNeighborsClassifier(n_neighbors = 7)
# Fit the classifier to the training data
knn.fit(X_train, y_train)
# Print the accuracy
print(knn.score(X_test, y_test))
- Okay so in a split second, this out of the box knn model predicts the hand written digits with over 98% accuracy.
- Thats impressive for sure
- I think I am on to the bginning of something magical here
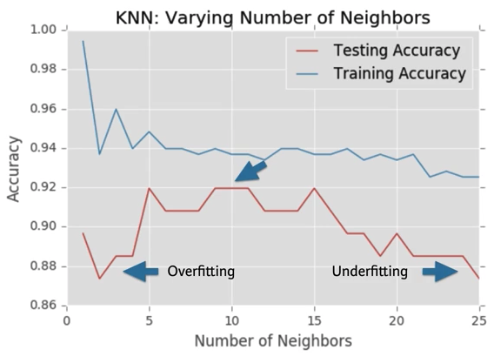
Overfitting and underfitting¶
- We will now construct such a model complexity curve for the digits dataset!
- In this exercise, we will compute and plot the training and testing accuracy scores for a variety of different neighbor values.
- By observing how the accuracy scores differ for the training and testing sets with different values of k, we will develop our intuition for overfitting and underfitting
# Setup arrays to store train and test accuracies
neighbors = np.arange(1, 15)
train_accuracy = np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
# Loop over different values of k
for i, k in enumerate(neighbors):
# Setup a k-NN Classifier with k neighbors: knn
knn = KNeighborsClassifier(n_neighbors = k)
# Fit the classifier to the training data
knn.fit(X_train, y_train)
#Compute accuracy on the training set
train_accuracy[i] = knn.score(X_train, y_train)
#Compute accuracy on the testing set
test_accuracy[i] = knn.score(X_test, y_test)
# Generate plot
plt.figure(figsize=(16,10))
plt.title('k-NN: Varying Number of Neighbors')
plt.plot(neighbors, test_accuracy, label = 'Testing Accuracy')
plt.plot(neighbors, train_accuracy, label = 'Training Accuracy')
plt.legend()
plt.xlabel('Number of Neighbors')
plt.ylabel('Accuracy')
plt.show()

- Welp, it looks like our value of 7 neighbors may be to many and creating an over simple model.
- Its seems to drop off after that.
- Probably 3 would be the best model to use here.
Regression¶
Introduction to regression¶
Boston housing data¶
file = 'https://assets.datacamp.com/production/course_1939/datasets/boston.csv'
boston = pd.read_csv(file)
boston.head()
Creating feature and target arrays¶
X = boston.drop('MEDV', axis = 1).values
y = boston['MEDV'].values
Predicting house value from a single feature¶
X_rooms = X[:,5]
type(X_rooms), type(y)
y = y.reshape(-1,1)
X_rooms = X_rooms.reshape(-1, 1)
Plotting house values vs. number of rooms¶
plt.figure(figsize=(16,10))
plt.plot(X_rooms, y,
marker='o',
markersize = 6,
markeredgewidth = 1,
markeredgecolor = 'k',
linestyle='none')
plt.ylabel('Value of house / 1000 ($)')
plt.xlabel('Number of rooms')
plt.show()

Fitting a regression model¶
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit(X_rooms, y)
prediction_space = np.linspace(
min(X_rooms),
max(X_rooms)).reshape(-1,1)
plt.figure(figsize=(16,10))
plt.plot(X_rooms, y,
marker='o',
markersize = 6,
markeredgewidth = 1,
markeredgecolor = 'k',
linestyle='none')
plt.plot(
prediction_space,
reg.predict(prediction_space),
color = 'black',
linewidth=3)
plt.ylabel('Value of house / 1000 ($)')
plt.xlabel('Number of rooms')
plt.show()

Importing data for supervised learning¶
- In this chapter, you will work with Gapminder data that we have consolidated into one CSV file available in the workspace as 'gapminder.csv'.
- Specifically, your goal will be to use this data to predict the life expectancy in a given country based on features such as the country's GDP, fertility rate, and population.
- As in Chapter 1, the dataset has been preprocessed.
- Since the target variable here is quantitative, this is a regression problem.
- To begin, you will fit a linear regression with just one feature: 'fertility', which is the average number of children a woman in a given country gives birth to.
- In later exercises, you will use all the features to build regression models.
- You need to import the data and get it into the form needed by scikit-learn.
- This involves creating feature and target variable arrays.
- Furthermore, since you are going to use only one feature to begin with, you need to do some reshaping using NumPy's .reshape() method.
- You will have to do this occasionally when working with scikit-learn so it is useful to practice.
file = 'https://assets.datacamp.com/production/course_1939/datasets/gm_2008_region.csv'
gapminder = pd.read_csv(file)
gapminder.head()
# Create arrays for features and target variable
y = gapminder.life
X = gapminder.fertility
# Print the dimensions of X and y before reshaping
print("Dimensions of y before reshaping: {}".format(y.shape))
print("Dimensions of X before reshaping: {}".format(X.shape))
# Reshape X and y
y = y.reshape(-1,1)
X = X.reshape(-1,1)
# Print the dimensions of X and y after reshaping
print("Dimensions of y after reshaping: {}".format(y.shape))
print("Dimensions of X after reshaping: {}".format(X.shape))
Exploring the Gapminder data¶
plt.figure(figsize=(14,10))
sns.heatmap(
gapminder.corr(),
square = True,
cmap="RdYlGn",
linewidths = 1)
plt.show()

gapminder.info()
gapminder.describe()
The basics of linear regression¶
Regression mechanics¶
- We will fit a line to the data with form:
- y = ax + b
- y = target
- x = single feature
- a,b = parameters of model
- How do we choose a and b?
- Define an error function for any given line
- Choose the line that minimized the error function
- This erro function can also be called a loss or cost function
The loss function¶
- Intitavely, we want the line to be as close to the actual data points as possible
- So we wish to minimize the vertical distance between the fit (line) and the data
- For each data point we calculate the vertical distance between it and the line
- This distance is called a residual
- We minimize the sum of the squares of the residuals
- I'd like to learn more about all the options here though
- this is called ordinary least squares (OLS)
- This is similar to minimizing the mean squarred error of the predictions on the training set
- When you call
.fit()on a linear regression model in scikit-learn it performs this OLS under the hood
Linear regression in higher dimension¶
- To fit a linear regression model here:
- y=a1x1+a2x2+b
- Need to specify 3 variables, a_1, a_2, and b
- In higher simension:
- y=a1x1+a2x2+a3x3+anxn+b
- Must specify coefficient for each feature and the variable b
- Scikit-learn API works exactly the same way:
- Pass two arrays: Features, and target
Linear regression on all features¶
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 42)
reg_all = linear_model.LinearRegression()
reg_all.fit(X_train, y_train)
y_pred = reg_all.predict(X_test)
reg_all.score(X_test, y_test)
- The default scoring method for linear regression is called r-squared
- Intuitiavely this feature quantifies the amount of variance in the target variable that is predicted from the feature variables
- Also not the you will likely never use linear regression out of the boc like this
- we will use regularization to place further constraints on the model coefficents
- we will cover this later in the chapter
Fit & predict for regression¶
gapminder.head()
X_fertility = gapminder.fertility.values.reshape(-1, 1)
y = gapminder.life.values
# Import LinearRegression
from sklearn.linear_model import LinearRegression
# Create the regressor: reg
reg = LinearRegression()
# Create the prediction space
prediction_space = np.linspace(
min(X_fertility),
max(X_fertility)
).reshape(-1,1)
# Fit the model to the data
reg.fit(X_fertility, y)
# Compute predictions over the prediction space: y_pred
y_pred = reg.predict(prediction_space)
# Print R^2
print(reg.score(X_fertility, y))
plt.figure(figsize=(16,10))
plt.plot(X_fertility, y,
marker='o',
markersize = 6,
color = 'lightblue',
markeredgewidth = 1,
markeredgecolor = 'k',
linestyle='none')
plt.plot(
prediction_space,
y_pred,
color = 'black',
linewidth=3)
plt.ylabel('Life Expectancy')
plt.xlabel('Fertility')
plt.show()

Train/test split for regression¶
- As you learned in Chapter 1, train and test sets are vital to ensure that your supervised learning model is able to generalize well to new data.
- This was true for classification models, and is equally true for linear regression models.
gapminder.head()
X = gapminder.drop(['life','Region'], axis = 1).values
y = gapminder.life.values
# Import necessary modules
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state=42)
# Create the regressor: reg_all
reg_all = LinearRegression()
# Fit the regressor to the training data
reg_all.fit(X_train, y_train)
# Predict on the test data: y_pred
y_pred = reg_all.predict(X_test)
# Compute and print R^2 and RMSE
print("R^2: {}".format(reg_all.score(X_test, y_test)))
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print("Root Mean Squared Error: {}".format(rmse))
- Cool, we have improved our model significantly by using all of the data
Cross-validation¶
- One issue with just doing 1 train and test validation
- Model performance is dependent on way the data is split
- Not representative of the models's ability to generalize
- Solution - Cross-validation
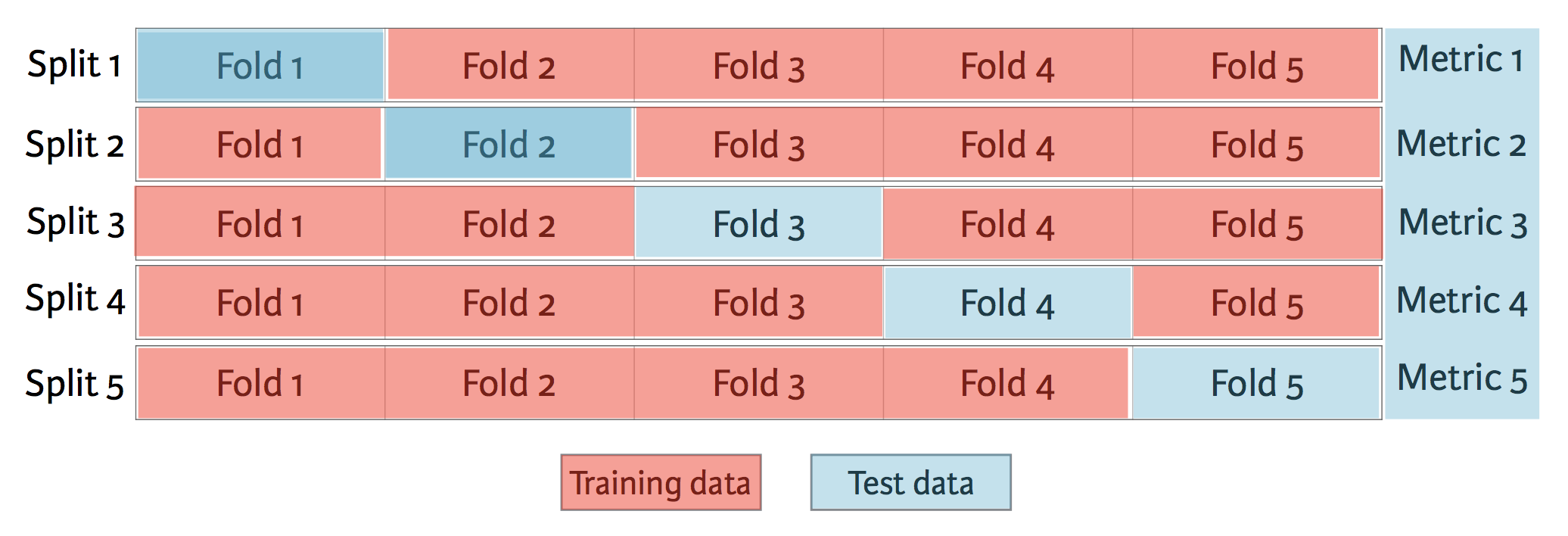
Cross-validation and model performance¶
- 5 folds = 5-fold CV
- 10 folds = 10-fold CV
- k folds = k-fold CV
- More folds = More computationally expensive
Cross-validation in scikit-learn¶
X = boston.drop('MEDV', axis = 1).values
y = boston['MEDV'].values
from sklearn.model_selection import cross_val_score
reg = linear_model.LinearRegression()
cv_results = cross_val_score(reg, X, y, cv = 5)
print(cv_results)
np.mean(cv_results)
5-fold cross-validation¶
Cross-validation is a vital step in evaluating a model.
- It maximizes the amount of data that is used to train the model
- as during the course of training, the model is not only trained, but also tested on all of the available data.
By default, scikit-learn's cross_val_score() function uses R2R2 as the metric of choice for regression.
- Since you are performing 5-fold cross-validation, the function will return 5 scores.
# Import the necessary modules
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
X = gapminder.drop(['life','Region'], axis = 1).values
y = gapminder.life.values
# Create a linear regression object: reg
reg = LinearRegression()
# Compute 5-fold cross-validation scores: cv_scores
cv_scores = cross_val_score(reg, X, y, cv = 5)
# Print the 5-fold cross-validation scores
print(cv_scores)
print("Average 5-Fold CV Score: {}".format(np.mean(cv_scores)))
K-Fold CV comparison¶
# Perform 3-fold CV
cvscores_3 = cross_val_score(reg, X, y, cv = 3)
print(np.mean(cvscores_3))
# Perform 10-fold CV
cvscores_10 = cross_val_score(reg, X, y, cv = 10)
print(np.mean(cvscores_10))
%timeit cross_val_score(reg, X, y, cv = 3)
%timeit cross_val_score(reg, X, y, cv = 10)
Regularized regression¶
Why regularize?¶
- Recall: Linear regression minimizes a loss function
- It chooses a coefficient for each feature value
- Large coefficients can lead to overfitting
- Penalizing large coeefficients: Regularization
- My explaination
- It sounds like what will inevitably happen is that our linear regression will overfit to some of the background noice. And the regularization penalizes the model when it gets too complex. So it keeps it more simple, which in general is more likely to fit future data better.
- Its kinda like penalizing a k-means with a higher k-neighbors because you already know intuitively that if it is too high, you are overfitting.
- I'm sure you can tweek the regularization parameter between none and a lot to control the complexity/simplicity of the model and create a complexity curve with cross validation. This will take some time but it would shows that you do need to keep you model simple at some level.
Rigde Regression¶
- Loss function = OLS Loss function + α∗∑ni=1a2i
- That is, the new loss function is the original plus the squared value of each coefficient times alpha.
- Alpha: parameter we need to choose
- Picking alpha here is similar to picking k in k-NN
- Hyperparameter tuning (more in chapter 3)
Alpha (also called lambda in the wild) controls model complexity
- Alpha = 0: We get back OLS (Can lead to overfitting)
- Very high alpha: Can lead to underfitting
My words
- If alpha is zero the regularization goes to zero.
- This means that the model will want to minimize coefficents that are not strongly fit rather than take the penalty.
- So when prediciting salary from a bunch of variables, the coefficient on shoe size is lowered as much as possible. The coefficient on education is high but it helps the model so much that it stays high, but maybe not quite as high as it would have been without regularization.
Ridge regression in scikit-learn¶
- We set alpha
- We also normalize the data
from sklearn.linear_model import Ridge
X = boston.drop('MEDV', axis = 1).values
y = boston['MEDV'].values
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 42)
ridge = Ridge(alpha=0.1, normalize=True)
ridge.fit(X_train, y_train)
ridge_pred = ridge.predict(X_test)
ridge.score(X_test, y_test)
Lasso regression¶
- Loss function = OLS loss function + α∗∑ni=1|ai|
- This is similar but we add the absolute value of each coefficient times alpha
from sklearn.linear_model import Lasso
X = boston.drop('MEDV', axis = 1).values
y = boston['MEDV'].values
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 42)
lasso = Lasso(alpha=0.1, normalize=True)
lasso.fit(X_train, y_train)
lasso_pred = lasso.predict(X_test)
lasso.score(X_test, y_test)
Lasso regression for feature selection¶
- Can be used to select important features of a dataset
- Shrinks the coefficients of less important features to exactly 0
Lasso for feature selection in sckkit-learn¶
names = boston.drop('MEDV', axis = 1).columns
lasso = Lasso(alpha=0.1)
lasso_coef = lasso.fit(X, y).coef_
_ = plt.plot(range(len(names)), lasso_coef)
_ = plt.xticks(range(len(names)), names, rotation=60)
_ = plt.ylabel('Coefficients')
plt.show()

- This is very important because it allows us to better communicate what matters in the model.
- You cant overstate how useful it is to hae the coefficients of the model to explain what matters.
Regularization I: Lasso¶
# Import Lasso
from sklearn.linear_model import Lasso
columns = gapminder.drop(['life','Region'], axis = 1).columns
X = gapminder.drop(['life','Region'], axis = 1).values
y = gapminder.life.values
plt.figure(figsize=(18,10))
for i in range(0,5):
# Instantiate a lasso regressor: lasso
lasso = Lasso(alpha = i*0.1, normalize = True)
# Fit the regressor to the data
lasso.fit(X, y)
# Compute and print the coefficients
lasso_coef = lasso.coef_
# Plot the coefficients
plt.plot(range(len(columns)), lasso_coef, label = str(round(i*0.1, 1)))
plt.xticks(range(len(columns)), columns.values, rotation=60)
plt.margins(0.02)
plt.legend()
plt.show()

- As alpha is increased you see many of the parameters being removed completely.
- Child_mortality is the most important
- It also looks like HIV and BMI_female may matter
- It seems weird how fertility can be so high and then drop out completely when alpha goes from 0 to .1
Regularization II: Ridge¶
- Lasso is great for feature selection, but when building regression models, Ridge regression should be your first choice.
- Recall that lasso performs regularization by adding to the loss function a penalty term of the absolute value of each coefficient multiplied by some alpha.
- This is also known as L1 regularization because the regularization term is the L1 norm of the coefficients.
- This is not the only way to regularize, however.
- If instead you took the sum of the squared values of the coefficients multiplied by some alpha - like in Ridge regression - you would be computing the L2 norm.
def display_plot(cv_scores, cv_scores_std):
fig = plt.figure(figsize=(18,10))
ax = fig.add_subplot(1,1,1)
ax.plot(alpha_space, cv_scores, marker = 'o')
std_error = cv_scores_std / np.sqrt(10)
ax.fill_between(alpha_space, cv_scores + std_error, cv_scores - std_error, alpha=0.2)
ax.set_ylabel('CV Score +/- Std Error')
ax.set_xlabel('Alpha')
ax.axhline(np.max(cv_scores), linestyle='--', color='.5')
ax.set_xlim([alpha_space[0], alpha_space[-1]])
ax.set_xscale('log')
plt.show()
X = gapminder.drop(['life','Region'], axis = 1).values
y = gapminder.life.values
# Import necessary modules
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# Setup the array of alphas and lists to store scores
alpha_space = np.logspace(-4, 0, 50)
ridge_scores = []
ridge_scores_std = []
# Create a ridge regressor: ridge
ridge = Ridge(normalize = True)
# Compute scores over range of alphas
for alpha in alpha_space:
# Specify the alpha value to use: ridge.alpha
ridge.alpha = alpha
# Perform 10-fold CV: ridge_cv_scores
ridge_cv_scores = cross_val_score(ridge, X, y, cv = 10)
# Append the mean of ridge_cv_scores to ridge_scores
ridge_scores.append(np.mean(ridge_cv_scores))
# Append the std of ridge_cv_scores to ridge_scores_std
ridge_scores_std.append(np.std(ridge_cv_scores))
# Display the plot
display_plot(ridge_scores, ridge_scores_std)

Fine-tuning your model¶
How good is your model?¶
Classification metrics¶
- Measuring model performance with accuracy:
- Fraction of correctly classified samples
- Not always a useful metric
Class imbalance example: Emails¶
- Spam classification
- 99% of emails are real, 1% are spam
- Could build a classifier that predicts ALL emails as real
- 99% accurate!
- But horrible at actually classifying spam
- Fails at its originial purpose
- Need more nuanced metrics
Diagnosing classification predictions¶
- Confusion matrix
- Which class you choose to be the positive class is up to you
- in the spam cas we could select spam because that is what we are trying to predict
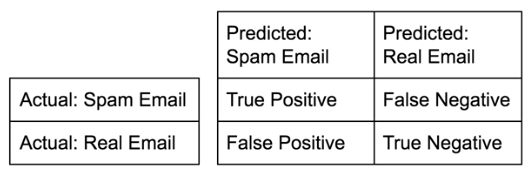
- Accuracy: True Pos+True NegSum of Matrix
Metrics from the confusion matrix¶
Precision:
- The correclty classified spam email divided by all classified spam emails
- High precision: Not many real emails predicted as spam
TPTP+FP
Recall:
- Also called sensitivity, hit rate, or true positive rate
- I like this better because it wont be 100% if you just classify 1 spam email correctly
- High recall: Predicted most spam emails correctly
TPTP+FN
F1 score:
- This is the harmonic mean of precision and recall
2∗precision∗recallprecision+recall
Confusion matrix in scikit-learn¶
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
X = iris.data
y = iris.target
knn = KNeighborsClassifier(n_neighbors = 8)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.4,
random_state = 42)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Metrics for classification¶
- The support is the number of samples of the true responses that lie in that class.
- In this exercise we will work with the PIMA Indians dataset obtained from the UCI Machine learning repository.
- The goal is to predict whether or not a given femaile patient will contract diabetes based on fetures such as BMI, age, and number of pregnancies
- Therefore, it is a binary classification problem.
- A target value of 0 indicates that the patient does not have diabetes, while a value of 1 indicates that the patient does have diabetes.
- The data set has already been preprocessed to deal with missing values.
file = 'https://assets.datacamp.com/production/course_1939/datasets/diabetes.csv'
diabetes = pd.read_csv(file)
diabetes.head()
# Import necessary modules
from sklearn.metrics import classification_report, confusion_matrix
X = diabetes.drop(['diabetes'], axis = 1).values
y = diabetes.diabetes.values
# Create training and test set
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.4,
random_state = 42)
# Instantiate a k-NN classifier: knn
knn = KNeighborsClassifier(n_neighbors = 6)
# Fit the classifier to the training data
knn.fit(X_train, y_train)
# Predict the labels of the test data: y_pred
y_pred = knn.predict(X_test)
# Generate the confusion matrix and classification report
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Logistic regression and the ROC curve¶
Logistic regression for binary classification¶
- Despite its name, logisitic regression is used for classification problems, not regression problems
- Its not predicting a value but a decision boundary.
- Logistic regression outputs probabilities
- If the probability 'p' is greater than 0.5:
- The data is labeled '1'
- If the probability 'p' is less than 0.5:
- The data is labeled '0'
- There is, in essense, a linear decision boundary where the pobability is 0.5
Logistic Regression steps¶
- These are the same as what we have done for the other methods
- Perform the necessary imports
- Instantiate the classifier
- Split your data into training and test sets
- Fit the model on your training data
- Predict on your test set
Logistic regression in scikit-learn¶
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
logreg = LogisticRegression()
y = vote_clean['party'].values
X = vote_clean.drop('party', axis=1).values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 42)
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
y_pred[:6]
Probability thresholds¶
- By default, logistic regression threshold = 0.5
- Not specific to logistic regression
- k-NN classifiers also have thresholds
- What happens if we vary the threshold?
- This is what the ROC curve shows us
Plotting the ROC curve¶
Notes:
- First I had an error that stated
- "ValueError: Data is not binary and pos_label is not specified"
- I have to convert the y_test array to be boolean. It originally is a label of democrat or republican.
- I can see that the republican label is associated with 1 so this is an easy change
y_test[0:6]
y_pred_prob[:6]
y_test_bool = y_test == 'republican'
y_test_bool[:6]
from sklearn.metrics import roc_curve
y_pred_prob = logreg.predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test_bool, y_pred_prob)
plt.figure(figsize=(18,10))
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr, tpr, label = 'logistic Regression')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Logisitc Regression ROC Curve')
plt.show()

Building a logistic regression model¶
# Import the necessary modules
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
X = diabetes.drop(['diabetes'], axis = 1).values
y = diabetes.diabetes.values
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state=42)
# Create the classifier: logreg
logreg = LogisticRegression()
# Fit the classifier to the training data
logreg.fit(X_train, y_train)
# Predict the labels of the test set: y_pred
y_pred = logreg.predict(X_test)
# Compute and print the confusion matrix and classification report
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Plotting an ROC curve¶
- Classification reports and confusion matrices are great methods to quantitatively evaluate model performance, while ROC curves provide a way to visually evaluate models.
- Most classifiers in scikit-learn have a .predict_proba() method which returns the probability of a given sample being in a particular class.
# Import necessary modules
from sklearn.metrics import roc_curve
# Compute predicted probabilities: y_pred_prob
y_pred_prob = logreg.predict_proba(X_test)[:,1]
# Generate ROC curve values: fpr, tpr, thresholds
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
# Plot ROC curve
plt.figure(figsize=(18,10))
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr, tpr)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.show()

Precision-recall Curve¶
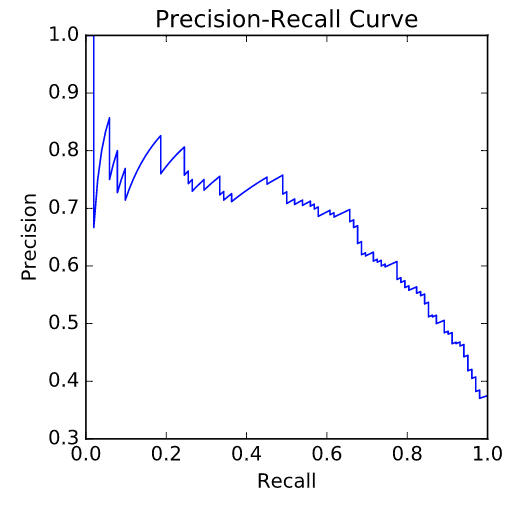
- A recall of 1 corresponds to a classifier with a low threshold in which all females who contract diabetes were correctly classified as such, at the expense of many misclassifications of those who did not have diabetes.
- Precision is undefined for a classifier which makes no positive predictions, that is, classifies everyone as not having diabetes.
- When the threshold is very close to 1, precision is also 1, because the classifier is absolutely certain about its predictions.
Area under the ROC curve¶
Area under the ROC curve (AUC)¶
- Larger area under the ROC curve = better model
- The top left is where you want your model to be. Catch all the true positives but make few or no false positives.
AUC in scikit-learn¶
from sklearn.metrics import roc_auc_score
logreg = LogisticRegression()
y = vote_clean['party'].values == 'republican'
X = vote_clean.drop('party', axis=1).values
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.4,
random_state = 42)
logreg.fit(X_train, y_train)
y_pred_prob = logreg.predict_proba(X_test)[:,1]
roc_auc_score(y_test, y_pred_prob)
AUC using cross-validation¶
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(logreg, X, y, cv = 5, scoring = 'roc_auc')
print(cv_scores)
AUC computation¶
- Say you have a binary classifier that in fact is just randomly making guesses.
- It would be correct approximately 50% of the time, and the resulting ROC curve would be a diagonal line in which the True Positive Rate and False Positive Rate are always equal.
- The Area under this ROC curve would be 0.5.
- If the AUC is greater than 0.5, the model is better than random guessing. Always a good sign!
# Import necessary modules
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import cross_val_score
X = diabetes.drop(['diabetes'], axis = 1).values
y = diabetes.diabetes.values
# Compute predicted probabilities: y_pred_prob
y_pred_prob = logreg.predict_proba(X_test)[:,1]
# Compute and print AUC score
print("AUC: {}".format(roc_auc_score(y_test, y_pred_prob)))
# Compute cross-validated AUC scores: cv_auc
cv_auc = cross_val_score(logreg, X, y, cv = 5, scoring = 'roc_auc')
# Print list of AUC scores
print("AUC scores computed using 5-fold cross-validation: {}".format(cv_auc))
Hyperparameter tuning¶
Hyperparmeter tuning¶
- Linear regresion: Choosing parmeters
- Ridge/lasso regression: Choosing alpha
- K-Nearest Neighbors: CHoosing n_neighbors
- Paramters like alpha and k: Hyperparameters
- Cannot be learned by fitting the model
Choosing the correct hyperparameter¶
- Hyperparameter tuning method
- Try a bunch of different hyperparmeter values
- Fit all of them separately
- See how well each performs
- Choose the best performing one
- This is the current fashion for doing it.
- If you come up with a better way, you many become famous
- Its essential to use cross-validation
- Using a single train test risks over fitting the hyperparameter to the test data
Grid search cross-validation¶
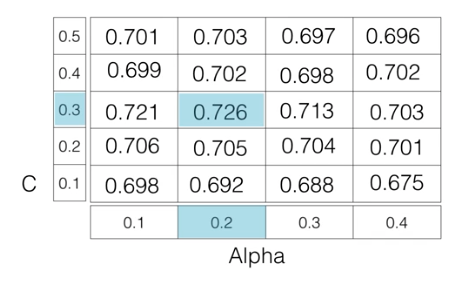
GridSearchCV in scikit-learn¶
from sklearn.model_selection import GridSearchCV
y = vote_clean['party'].values
X = vote_clean.drop('party', axis=1).values
param_grid = {'n_neighbors':np.arange(1,50)}
knn = KNeighborsClassifier()
knn_cv = GridSearchCV(knn, param_grid, cv=5)
knn_cv.fit(X,y)
print(knn_cv.best_params_)
print(knn_cv.best_score_)
Hyperparameter tuning with GridSearchCV¶
- Hugo demonstrated how to tune the n_neighbors parameter of the KNeighborsClassifier() using GridSearchCV on the voting dataset.
- You will now practice this yourself, but by using logistic regression on the diabetes dataset instead!
- Like the alpha parameter of lasso and ridge regularization that you saw earlier, logistic regression also has a regularization parameter:
C.Ccontrols the inverse of the regularization strength, and this is what you will tune in this exercise.- A large
Ccan lead to an overfit model, while a small CC can lead to an underfit model.
- Here we are just practicing using the grid.
- In practice we would be using trianing and test data
X = diabetes.drop(['diabetes'], axis = 1).values
y = diabetes.diabetes.values
# Import necessary modules
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Setup the hyperparameter grid
c_space = np.logspace(-5, 8, 15)
param_grid = {'C': c_space}
# Instantiate a logistic regression classifier: logreg
logreg = LogisticRegression()
# Instantiate the GridSearchCV object: logreg_cv
logreg_cv = GridSearchCV(logreg, param_grid, cv=5)
# Fit it to the data
logreg_cv.fit(X,y)
# Print the tuned parameters and score
print("Tuned Logistic Regression Parameters: {}".format(logreg_cv.best_params_))
print("Best score is {}".format(logreg_cv.best_score_))
Hyperparameter tuning with RandomizedSearchCV¶
- GridSearchCV can be computationally expensive
- especially if you are searching over a large hyperparameter space and dealing with multiple hyperparameters.
A solution to this is to use RandomizedSearchCV, in which not all hyperparameter values are tried out.
- Instead, a fixed number of hyperparameter settings is sampled from specified probability distributions.
Here, we are using the Decision Tree, because its suited to the Random search.
- Don't worry about the specifics of how this model works, for now.
- Just like k-NN, linear regression, and logistic regression, decision trees in scikit-learn have .fit() and .predict() methods that you can use in exactly the same way as before.
- Decision trees have many parameters that can be tuned, such as max_features, max_depth, and min_samples_leaf.
- This makes it an ideal use case for RandomizedSearchCV.
# Import necessary modules
from scipy.stats import randint
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import RandomizedSearchCV
# Setup the parameters and distributions to sample from: param_dist
param_dist = {"max_depth": [3, None],
"max_features": randint(1, 9),
"min_samples_leaf": randint(1, 9),
"criterion": ["gini", "entropy"]}
# Instantiate a Decision Tree classifier: tree
tree = DecisionTreeClassifier()
# Instantiate the RandomizedSearchCV object: tree_cv
tree_cv = RandomizedSearchCV(tree, param_dist, cv=5)
# Fit it to the data
tree_cv.fit(X,y)
# Print the tuned parameters and score
print("Tuned Decision Tree Parameters: {}".format(tree_cv.best_params_))
print("Best score is {}".format(tree_cv.best_score_))
- You'll see a lot more of decision trees and RandomizedSearchCV as you continue your machine learning journey.
- Note that
RandomizedSearchCVwill never outperformGridSearchCV.- Instead, it is valuable because it saves on computation time.
Hold-out set for final evaluation¶
Hold-out set reasoning¶
- How well can the model perform on never before seen data?
- Using ALL data for cross-validation is not ideal
- Split data into training and hold-out set at the beginning
- Perform grid search cross-validation on training set
- Choose best hyperparameters and evaluate on hold-out set
Hold-out set in practice I: Classification¶
- In addition to
C, logistic regression has a 'penalty' hyperparameter which specifies whether to use 'l1' or 'l2' regularization. - Your job in this exercise is
- to create a hold-out set,
- tune the 'C' and 'penalty' hyperparameters of a logistic regression classifier using GridSearchCV on the training set
- evaluate its performance against the hold-out set.
# Set features and target data
X = diabetes.drop(['diabetes'], axis = 1).values
y = diabetes.diabetes.values
# Import necessary modules
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Create the hyperparameter grid
c_space = np.logspace(-5, 8, 15)
param_grid = {'C':c_space, 'penalty': ['l1', 'l2']}
# Instantiate the logistic regression classifier: logreg
logreg = LogisticRegression()
# Create train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.4,
random_state = 42)
# Instantiate the GridSearchCV object: logreg_cv
logreg_cv = GridSearchCV(logreg, param_grid, cv = 5)
# Fit it to the training data
logreg_cv.fit(X_train, y_train)
# Print the optimal parameters and best score
print("Tuned Logistic Regression Parameter: {}".format(logreg_cv.best_params_))
print("Tuned Logistic Regression Accuracy: {}".format(logreg_cv.best_score_))
Hold-out set in practice II: Regression¶
- Lasso used the
L1penalty to regularize, while ridge used theL2penalty. - There is another type of regularized regression known as the elastic net.
- In elastic net regularization, the penalty term is a linear combination of the
L1andL2penalties:
- In elastic net regularization, the penalty term is a linear combination of the
a∗L1+b∗L2
- In scikit-learn, this term is represented by the 'l1_ratio' parameter:
- An 'l1_ratio' of 1 corresponds to an
L1penalty, and anything lower is a combination ofL1andL2.
- An 'l1_ratio' of 1 corresponds to an
X = gapminder.drop(['life','Region'], axis = 1).values
y = gapminder.life.values
# Import necessary modules
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV, train_test_split
# Create train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.4,
random_state = 42)
# Create the hyperparameter grid
l1_space = np.linspace(0, 1, 30)
param_grid = {'l1_ratio': l1_space}
# Instantiate the ElasticNet regressor: elastic_net
elastic_net = ElasticNet()
# Setup the GridSearchCV object: gm_cv
gm_cv = GridSearchCV(elastic_net, param_grid, cv=5)
# Fit it to the training data
gm_cv.fit(X_train, y_train)
# Predict on the test set and compute metrics
y_pred = gm_cv.predict(X_test)
r2 = gm_cv.score(X_test, y_test)
mse = mean_squared_error(y_test, y_pred)
print("Tuned ElasticNet l1 ratio: {}".format(gm_cv.best_params_))
print("Tuned ElasticNet R squared: {}".format(r2))
print("Tuned ElasticNet MSE: {}".format(mse))
Preprocessing and pipelines¶
Preprocessing data¶
Dealing with categorical features¶
- Scikit-learn will not accept categorical features by default
- Need to encode categorical features numerically
- Convert to 'dummy variable', 1 for each category with boolean values
- 0: Observation was NOT that category
- 1: Observation was that category
Dummy Variables¶
- Example: Lets say we have the cars dataset with an 'origin' field
- This field has 3 categorical values ('US','Europe','Asia')
- We would created 3 columns with headers US, Europ, Asia and boolean values for if the car is made in that continent
- But we actually are duplicating data here. The origin_Europe column would be redundant.
- So we remove it and just have US and Asia columns
- Some models would get messed up with this duplicate data
Dealing with categorical features in Python¶
- scikit-learn: OneHotEncoder()
- pandas: get_dummies()
Encoding dummy variables¶
file = 'https://assets.datacamp.com/production/course_1939/datasets/auto.csv'
auto = pd.read_csv(file)
auto.head()
auto_origin = pd.get_dummies(auto)
auto_origin.head()
## Using drop_first to reduce duplication
auto_origin = pd.get_dummies(auto, drop_first=True)
auto_origin.head()
## Or you can pick which to drop explicity
auto_origin = pd.get_dummies(auto)
auto_origin = auto_origin.drop('origin_Asia', axis = 1)
auto_origin.head()
Linear regression with dummy variables¶
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
X = auto_origin.drop(['mpg'], axis = 1).values
y = auto_origin.mpg.values
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 42)
ridge = Ridge(alpha = 0.5, normalize = True)
ridge.fit(X_train, y_train)
ridge.score(X_test, y_test)
Exploring categorical features¶
gapminder.head()
# Create a boxplot of life expectancy per region
gapminder.boxplot('life', 'Region', rot=60)
# Show the plot
plt.show()

Creating dummy variables¶
# Create dummy variables: gapminder_region
gapminder_region = pd.get_dummies(gapminder)
# Print the columns of gapminder_region
print(gapminder_region.columns)
# Create dummy variables with drop_first=True: gapminder_region
gapminder_region = pd.get_dummies(gapminder, drop_first = True)
# Print the new columns of gapminder_region
print(gapminder_region.columns)
Regression with categorical features¶
X = gapminder_region.drop(['life'], axis = 1).values
y = gapminder_region.life.values
# Import necessary modules
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# Instantiate a ridge regressor: ridge
ridge = Ridge(alpha = 0.5, normalize = True)
# Perform 5-fold cross-validation: ridge_cv
ridge_cv = cross_val_score(ridge, X, y, cv = 5)
# Print the cross-validated scores
print(ridge_cv)
Handling missing data¶
- Data can be missing in the real world for many reasons
- no observation was made, recording error, or data corruption
- Either way we need to deal with it.
- But watch out. Make sure to explore the data well. Not all missing data is labeled as NaN
- It could be a 0, -1, 99999 or some string like 'None'
PIMA Indians dataset¶
- It looks good when using
info, but... - Whoa, look a those zeros in insulin and tricepts, and bmi. huh
diabetes.info()
diabetes.head(15)
np.sum(diabetes == 0)
Dropping missing data¶
- pregnancies can be zero. and diabetes
- but the rest should not be zero.
- Looks like we have all the data for age and dpf
- we need to replace zeros with NaN and then we can fugure out what to do with those values
diabetes.glucose.replace(0, np.nan, inplace=True)
diabetes.diastolic.replace(0, np.nan, inplace=True)
diabetes.triceps.replace(0, np.nan, inplace=True)
diabetes.insulin.replace(0, np.nan, inplace=True)
diabetes.bmi.replace(0, np.nan, inplace=True)
diabetes.info()
- If we just drop all rows where a single value is missinging we will just have half the data left.
- We would be throwing out a lot of good data. Thats not ideal
- Similarly, if we threw away columns with missing data we would drop tons of useful data and most of our features. Also a bad idea
df = diabetes.dropna()
df.shape
Impute missing data¶
- Making an educated guess about the missing values
- Example: Using the mean of the non-missing entries
- Imputers are known as transformers. There are other models that use the
transform()method to transform data - Once we have tranformed the data we can fit a model to it. Or, as we will see, we can do it all at once with pipelines
# X = diabetes.drop(['diabetes'], axis = 1).values
# y = diabetes.diabetes.values
diabetes.info()
X = diabetes.drop(['diabetes'], axis = 1).values
y = diabetes.diabetes.values
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit(X)
X = imp.transform(X)
Imputing within a pipeline¶
- Note that in a pipeline each step must be a transformer and the last must be an estimator such as a classifier, regressor, or transformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import Imputer
X = diabetes.drop(['diabetes'], axis = 1).values
y = diabetes.diabetes.values
imp = Imputer(missing_values = 'NaN', strategy='mean', axis=0)
logreg = LogisticRegression()
steps = [('imputation', imp),
('logistic_regression', logreg)]
pipeline = Pipeline(steps)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 42)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
pipeline.score(X_test, y_test)
Dropping missing data¶
file = 'https://assets.datacamp.com/production/course_1939/datasets/house-votes-84.csv'
vote = pd.read_csv(file, names = vote_clean_columns)
vote.head()
# Convert '?' to NaN
vote[vote == '?'] = np.nan
# Print the number of NaNs
print(vote.isnull().sum())
# Print shape of original DataFrame
print("Shape of Original DataFrame: {}".format(vote.shape))
# Drop missing values and print shape of new DataFrame
vote = vote.dropna()
# Print shape of new DataFrame
print("Shape of DataFrame After Dropping All Rows with Missing Values: {}".format(vote.shape))
Imputing missing data in a ML Pipeline I¶
- Imputation can be seen as the first step of this machine learning process, the entirety of which can be viewed within the context of a pipeline.
Scikit-learn provides a pipeline constructor that allows you to piece together these steps into one process and thereby simplify your workflow.
You'll now practice setting up a pipeline with two steps: the imputation step, followed by the instantiation of a classifier.
- You've seen three classifiers in this course so far: k-NN, logistic regression, and the decision tree.
- You will now be introduced to a fourth one - the Support Vector Machine, or SVM.
# Import the Imputer module
from sklearn.preprocessing import Imputer
from sklearn.svm import SVC
# Setup the Imputation transformer: imp
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
# Instantiate the SVC classifier: clf
clf = SVC()
# Setup the pipeline with the required steps: steps
steps = [('imputation', imp),
('SVM', clf)]
Imputing missing data in a ML Pipeline II¶
vote = pd.read_csv(file, names = vote_clean_columns)
vote.head()
vote[vote == '?'] = np.nan
vote[vote == 'y'] = True
vote[vote == 'n'] = False
vote.head()
y = vote_clean['party'].values
X = vote_clean.drop('party', axis=1).values
# Import necessary modules
from sklearn.preprocessing import Imputer
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
# Setup the pipeline steps: steps
steps = [('imputation', Imputer(missing_values='NaN', strategy='most_frequent', axis=0)),
('SVM', SVC())]
# Create the pipeline: pipeline
pipeline = Pipeline(steps)
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 42)
# Fit the pipeline to the train set
pipeline.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = pipeline.predict(X_test)
# Compute metrics
print(classification_report(y_test, y_pred))
Centering and scaling¶
Why scale your data?¶
- Many models use some form of distance to inform them
- Features on larger scales can unduly influence the model
- Example: k-NN uses distance expllicitly when making predictions
- We want features to be on a similar scale
- Normalizing (or scaling and centering)
Ways to normalize your data¶
- Standardization: Subtract the mean and divide by variance
- All features are centered around zero and have variance one
- Can also subtract the minimum and divide by the range
- Minimum zero and maximum one
- Can also normalize so the data ranges from -1 to +1
- We will cover standardization:
- see scikit-learn docs for further details on other approaches
Scaling in scikit-learn¶
file = 'https://assets.datacamp.com/production/course_1939/datasets/winequality-red.csv'
redwine = pd.read_csv(file, sep = ';')
redwine.head()
X = redwine.drop('quality', axis = 1).values
y = redwine.quality.values < 5
from sklearn.preprocessing import scale
X_scaled = scale(X)
print(np.mean(X), np.std(X))
print(np.mean(X_scaled), np.std(X_scaled))
Scaling in a pipeline¶
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
steps = [('scaler', StandardScaler()),
('knn', KNeighborsClassifier())]
pipeline = Pipeline(steps)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.2,
random_state = 21)
knn_scaled = pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
accuracy_score(y_test, y_pred)
knn_unscaled = KNeighborsClassifier().fit(X_train, y_train)
knn_unscaled.score(X_test, y_test)
Cross Validation and scaling in a pipeling¶
steps = [('scaler', StandardScaler()),
('knn', KNeighborsClassifier())]
pipeline = Pipeline(steps)
parameters = {'knn__n_neighbors' : np.arange(1, 50)}
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.2,
random_state = 21)
cv = GridSearchCV(pipeline, param_grid = parameters)
cv.fit(X_train, y_train)
y_pred = cv.predict(X_test)
print(cv.best_params_)
print(cv.score(X_test, y_test))
print(classification_report(y_test, y_pred))
Centering and scaling your data¶
- In the video, Hugo demonstrated how significantly the performance of a model can improve if the features are scaled.
- Note that this is not always the case: In the Congressional voting records dataset, for example, all of the features are binary. In such a situation, scaling will have minimal impact.
file = 'https://assets.datacamp.com/production/course_1939/datasets/white-wine.csv'
whitewine = pd.read_csv(file)
whitewine.head()
X = whitewine.drop('quality', axis = 1).values
y = whitewine.quality.values > 5
# Import scale
from sklearn.preprocessing import scale
# Scale the features: X_scaled
X_scaled = scale(X)
# Print the mean and standard deviation of the unscaled features
print("Mean of Unscaled Features: {}".format(np.mean(X)))
print("Standard Deviation of Unscaled Features: {}".format(np.std(X)))
print('--------------------------------')
# Print the mean and standard deviation of the scaled features
print("Mean of Scaled Features: {}".format(np.mean(X_scaled)))
print("Standard Deviation of Scaled Features: {}".format(np.std(X_scaled)))
Centering and scaling in a pipeline¶
# Import the necessary modules
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# Setup the pipeline steps: steps
steps = [('scaler', StandardScaler()),
('knn', KNeighborsClassifier())]
# Create the pipeline: pipeline
pipeline = Pipeline(steps)
# Create train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 42)
# Fit the pipeline to the training set: knn_scaled
knn_scaled = pipeline.fit(X_train, y_train)
# Instantiate and fit a k-NN classifier to the unscaled data
knn_unscaled = KNeighborsClassifier().fit(X_train, y_train)
# Compute and print metrics
print('Accuracy with Scaling: {}'.format(knn_scaled.score(X_test, y_test)))
print('Accuracy without Scaling: {}'.format(knn_unscaled.score(X_test, y_test)))
Bringing it all together I: Pipeline for classification¶
# Setup the pipeline
steps = [('scaler', StandardScaler()),
('SVM', SVC())]
pipeline = Pipeline(steps)
# Specify the hyperparameter space
parameters = {'SVM__C':[1, 10, 100],
'SVM__gamma':[0.1, 0.01]}
# Create train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.2,
random_state = 21)
# Instantiate the GridSearchCV object: cv
cv = GridSearchCV(pipeline, param_grid = parameters, cv = 3)
# Fit to the training set
cv.fit(X_train, y_train)
# Predict the labels of the test set: y_pred
y_pred = cv.predict(X_test)
# Compute and print metrics
print("Accuracy: {}".format(cv.score(X_test, y_test)))
print('--------------------------------')
print(classification_report(y_test, y_pred))
print('--------------------------------')
print("Tuned Model Parameters: {}".format(cv.best_params_))
Bringing it all together II: Pipeline for regression¶
gapminder_region = pd.get_dummies(gapminder, drop_first = True)
X = gapminder_region.drop(['life'], axis = 1).values
y = gapminder_region.life.values
# Setup the pipeline steps: steps
steps = [('imputation', Imputer(missing_values='NaN', strategy='mean', axis=0)),
('scaler', StandardScaler()),
('elasticnet', ElasticNet())]
# Create the pipeline: pipeline
pipeline = Pipeline(steps)
# Specify the hyperparameter space
parameters = {'elasticnet__l1_ratio':np.linspace(0,1,30)}
# Create train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.4,
random_state = 42)
# Create the GridSearchCV object: gm_cv
gm_cv = GridSearchCV(pipeline, param_grid = parameters, cv = 3)
# Fit to the training set
gm_cv.fit(X_train, y_train)
# Compute and print the metrics
r2 = gm_cv.score(X_test, y_test)
print("Tuned ElasticNet Alpha: {}".format(gm_cv.best_params_))
print("Tuned ElasticNet R squared: {}".format(r2))
Final thoughts¶
- For more info checkout:
- Scikit documentation
- 'Introduction to Machine Learning in Python' (has a lizard on it)