Deep Learning in Python¶
- William Surles
- 2017-12-22
- Datacamp class
- https://www.datacamp.com/courses/deep-learning-in-python
Whats Covered¶
Basics of deep learning and neural networks
- Introduction to deep learning
- Forward propagation
- Activation functions
- Deeper networks
Otimizing a neural network with backward propagation
- The need for optimization
- Gradient descent
- Backpropagation
- Backpropagation in practice
Building deep learning models with keras
- Creating a keras model
- Compiling and fitting a model
- Classification models
- Using models
Fine-tuning keras models
- Understanding model optimization
- Model validation
- Thinking about model capacity
- Stepping up to images
- Final thoughts
Additional Resources¶
- Check this wiki page on data sets for machine learning research
Libraries and Data¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Basics of deep learning and neural networks¶
Introduction to deep learning¶
Interactions¶
- Imagine you work for a bank and you need to predict the number of transactions each customer will make next year
- I linear regression model could give you an answer based on weighting certain factors, like age or number of kids. But it does not do a great job of capturing the intricate interactions of the real world process.
- Neural networks account for interactions really well
- Deep learning uses especially powerfyl neural networks
- This works well for the intricacies in many types of data like...
- Text, images, video, audio, source code, etc
Course structure¶
- First to chapters focus on conceptual knowledge
- debug and tune deep learing models on conventional prediction problems
- Lay the foundation for progressin towards modern applications
- Chp 3 and 4 covers keras
- Build and tune models in keras
Forward propagation¶
- There are good pictures in the slides. I'll just explain it
- Each link between nodes is given a weighting
- the inputs times the weights added together equals the value at the next node
- this is essentially a dot product of inputs and weights (yay matrix math)
- keep doing this until you get the output value at the end.
- This happens for one data point (or row, or observation) at a time. The output is the prediction for the data point
- The trick is to get all the weightings correct so the model is accurate.
Coding the forward propagation algorithm¶
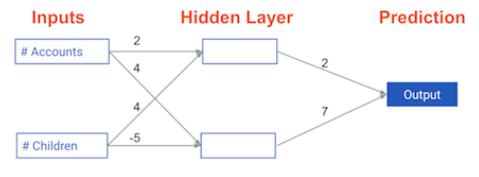
input_data = np.array([3, 5])
weights = {'node_0': np.array([2, 4]), 'node_1': np.array([ 4, -5]), 'output': np.array([2, 7])}
# Calculate node 0 value: node_0_value
node_0_value = (input_data * weights['node_0']).sum()
# Calculate node 1 value: node_1_value
node_1_value = (input_data * weights['node_1']).sum()
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_value, node_1_value])
# Calculate output: output
output = (hidden_layer_outputs * weights['output']).sum()
# Print output
print(output)
- Well, that was easy. : )
- -39 seems like a wierd value but I'm sure will fix that later
- This is just for one observation with two variables
- And there is just one layer with 2 nodes.
- About as simple as you can get.
- But this is about as complex as most regression models I guess.
Activation functions¶
- Activation functions are applied at the node
- The modify the node input value to something different for the node output
- This is used to capture non-linearity in the the model
- They have been shown to greatly increase the perofrmance of a neural network
- For a long time
tanh()was used as the standard activation function - Now ReLU (Rectified Linear Activation) is the standard
- A ReLu function is basically just
max(0, input) - Its prevents negative numbers at the node
- A ReLu function is basically just
The Rectified Linear Activation Function¶
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(0, input)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
model_output = (hidden_layer_outputs * weights['output']).sum()
# Print model output
print(model_output)
Applying the network to many observations/rows of data¶
input_data = [np.array([3, 5]), np.array([ 1, -1]), np.array([0, 0]), np.array([8, 4])]
weights = {
'node_0': np.array([2, 4]),
'node_1': np.array([ 4, -5]),
'output': np.array([2, 7])}
# Define predict_with_network()
def predict_with_network(input_data_row, weights):
# Calculate node 0 value
node_0_input = (input_data_row * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value
node_1_input = (input_data_row * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output
input_to_final_layer = (hidden_layer_outputs * weights['output']).sum()
model_output = relu(input_to_final_layer)
# Return model output
return(model_output)
# Create empty list to store prediction results
results = []
for input_data_row in input_data:
# Append prediction to results
results.append(predict_with_network(input_data_row, weights))
# Print results
print(results)
Deeper networks¶
- Deeper networks just have more layers
- 5- 10 maybe
- At pone point 15 was the cutting edge
- Now you could see 1000 hidden layers
- Its just about proccessing power
- These work well with parallel processing so you can scale out for the large networks
- The more layers the more complex the features get
- At first the model may find things like lines, then shapes, maybe even an eye
- Then it may recognize a face
- Then different faces like human or cat, or differnt people.
- I'm sure this is how google and face book do face recognition
Multi-layer neural networks¶
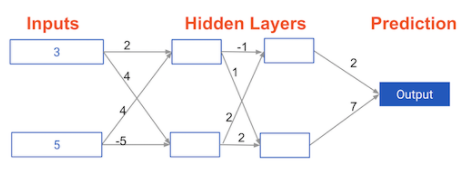
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([ 4, -5]),
'node_1_0': np.array([-1, 2]),
'node_1_1': np.array([1, 2]),
'output': np.array([2, 7])}
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data * weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs * weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs * weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs * weights['output']).sum()
# Return model_output
return(model_output)
output = predict_with_network(input_data)
print(output)
Representations are learned¶
How are the weights that deterimine the features/interaction in Neural Networks created>
- The model training process sets them to optimize predictive accuracy
Otimizing a neural network with backward propagation¶
The need for optimization¶
- The weights are how you optimize the neural network.
- Change the weights until the output is correct
Predictions with multiple points¶
- Making acurate predictions gets harder with more points
- At any set of weights, there are many values of the error
- ... corresponding to the many points we make predictions for
Loss funciton¶
- Aggregates errors in predictions from many data points into single number
- Measure of model's predictive performance
- Could be mean squarred error
- Lower loss function value means a better model
- Goal: Find the weights thta five the lowest value for the loss function
- Gradient descent is how you find the lowest value
Gradient descent¶
- Imaginge you are in a pitch dark field
- you want to find the lowest point
- Feel the ground to see how it slopes
- Take a small step downhill
- Repeat until it is uphill in every direction
Gradient descent steps¶
- Start at random point
- Until yo are somewhere flat:
- Find the slope
- Take a step downhill
Coding how weight changes affect accuracy¶
def predict_with_network(input_data, weights):
# Calculate node 0 in the first hidden layer
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 in the first hidden layer
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_0_outputs
hidden_outputs = np.array([node_0_output, node_1_output])
# Calculate model output: model_output
model_output = (hidden_outputs * weights['output']).sum()
# Return model_output
return(model_output)
# The data point you will make a prediction for
input_data = np.array([0, 3])
# Sample weights
weights_0 = {'node_0': [2, 1],
'node_1': [1, 2],
'output': [1, 1]
}
# The actual target value, used to calculate the error
target_actual = 3
# Make prediction using original weights
model_output_0 = predict_with_network(input_data, weights_0)
# Calculate error: error_0
error_0 = model_output_0 - target_actual
# Create weights that cause the network to make perfect prediction (3): weights_1
weights_1 = {'node_0': [2, 1],
'node_1': [1, 2],
'output': [1, 0]
}
# Make prediction using new weights: model_output_1
model_output_1 = predict_with_network(input_data, weights_1)
# Calculate error: error_1
error_1 = model_output_1 - target_actual
# Print error_0 and error_1
print(error_0)
print(error_1)
Scaling up to multiple data points¶
input_data = [np.array([0, 3]), np.array([1, 2]), np.array([-1, -2]), np.array([4, 0])]
target_actuals = [1, 3, 5, 7]
weights_0 = {'node_0': [2, 1],
'node_1': [1, 2],
'output': [1, 1]}
weights_1 = {'node_0': [2, 1],
'node_1': [ 1. , 1.5],
'output': [ 1. , 1.5]}
from sklearn.metrics import mean_squared_error
# Create model_output_0
model_output_0 = []
# Create model_output_0
model_output_1 = []
# Loop over input_data
for row in input_data:
# Append prediction to model_output_0
model_output_0.append(predict_with_network(row, weights_0))
# Append prediction to model_output_1
model_output_1.append(predict_with_network(row, weights_1))
# Calculate the mean squared error for model_output_0: mse_0
mse_0 = mean_squared_error(target_actuals, model_output_0)
# Calculate the mean squared error for model_output_1: mse_1
mse_1 = mean_squared_error(target_actuals, model_output_1)
print(model_output_0)
print(model_output_1)
print('target actuals:')
print(target_actuals)
# Print mse_0 and mse_1
print("Mean squared error with weights_0: %f" %mse_0)
print("Mean squared error with weights_1: %f" %mse_1)
Gradient descent¶
- If the slope is positive:
- Going opposite the slope means moving to lower numbers
- Subtract the slope from the current value
- Too big a step might lead us astray
- Solution: learning rate
- Update each weight by subtracting learning rate * slope
- Learning rates are frequently around 0.01
Slope calculation example¶
- to calculate the slope for a weight, need to multiply 3 things:
- slope of the loss function wrt value at the node we feed into
- the valye of the node that feeds into our weight
- slope of the activation functino wrt value we feed into
- example
- node = 3, weight = 2, output = 4, actual target value = 10
- lets step through those 3 things:
- slope of mean-squarred loss funciton wrt prediciton:
- 2 (Predictied Value = Actual Value) = 2 Error = 2 * -4
- the vale of the node that feeds into our weight
- 2 -4 3 = -24
- slope of the activation functino wrt value we feed into
- We don't have an activation function so ignore that here
- if learning rate is 0.01 the new wieght would be
- 2 - 0.01(-24) = 2.24
- this will give us better model and will continue to get better as we repeat this process
- We would repeat this process separately for each weight, then update them simultaneously with the respective deriviative
Calculating slopes¶
- When plotting the mean-squared error loss function against predictions, the slope is 2 x (y-xb), or 2 input_data error.
- Note that x and b may have multiple numbers (x is a vector for each data point, and b is a vector).
- In this case, the output will also be a vector, which is exactly what you want.
- In our example we have 3 input nodes and one prediciton node as the target
weights = np.array([0, 2, 1])
input_data = np.array([1, 2, 3])
target = 0
# Calculate the predictions: preds
preds = (weights * input_data).sum()
print("pred:", preds)
print("target:", target)
# Calculate the error: error
error = preds - target
# Calculate the slope: slope
slope = 2 * error * input_data
# Print the slope
print(slope)
Improving model weights¶
# Set the learning rate: learning_rate
learning_rate = 0.01
# Update the weights: weights_updated
weights_updated = weights - (slope * learning_rate)
# Get updated predictions: preds_updated
preds_updated = (weights_updated * input_data).sum()
# Calculate updated error: error_updated
error_updated = preds_updated - target
# Print the original error
print(error)
# Print the updated error
print(error_updated)
Making multiple updates to weights¶
- Lets clean up this process so we can do this multiple times easily
- We are wrapping the error and slope calculations in functions
def get_error(input_data, target, weights):
preds = (weights * input_data).sum()
error = preds - target
return(error)
def get_slope(input_data, target, weights):
error = get_error(input_data, target, weights)
slope = 2 * input_data * error
return(slope)
def get_mse(input_data, target, weights):
errors = get_error(input_data, target, weights)
mse = np.mean(errors**2)
return(mse)
n_updates = 20
mse_hist = []
# Iterate over the number of updates
for i in range(n_updates):
# Calculate the slope: slope
slope = get_slope(input_data, target, weights)
# Update the weights: weights
weights = weights - slope * 0.01
# Calculate mse with new weights: mse
mse = get_mse(input_data, target, weights)
# Append the mse to mse_hist
mse_hist.append(mse)
# Plot the mse history
plt.plot(mse_hist)
plt.xlabel('Iterations')
plt.ylabel('Mean Squared Error')
plt.show()

Backpropagation¶
- Allows gradient descent to update all weights in neural network (by getting gradients for all weights)
- Comes from chain rule of calculus
- Important to understand the process, but you will generally use a library that implements this
Backpropagation process¶
- Trying to estimate the slope of the loss function wrt each weight
- Do forward propagation to calculate predictions and errors first, before we do backpropagation
- Go back one layer at a time
- Gradients for weight is product of:
- Node value feeding into that weight
- We know this from the calculation when doing forward propagation
- Slope of loss function wrt node it feeds into
- We just calculated this in the back propagation process.
- Slope of activation function at the node it feeds into
- For the ReLU activation function this is 0 if the value is negative and 1 if its positive
- Node value feeding into that weight
- We need to also keep track of the slopes of the loss funciton wrt node values
- Slope of node values are just the sum of the slopes for all weights that come out of them
The relationship between forward and backward propagation¶
- its 1 to 1
- Each time you generate predictions using forward propagation, you updated the weights using backward propagation.
Thinking about backward propagation¶
- If your predictions were all exactly right, and your errors were all exactly 0, the slope of the loss function with respect to your predictions would also be 0.
- In that circumstance, the updates to all weights in the newtwork would also be 0.
Backpropagation in practice¶
- See a simple example of backpropagtion in the slides
Calculating slopes associated with any weight¶
- Gradients for weight is product of:
- Node value feeding into that weight
- Slope of activation function for the node being fed into
- This is simple the sum of slopes of weights coming out of node
- Slope of loss function wrt output node
- For relu this is 0 if negative and 1 if positive value at node
Backpropagation: Recap¶
- Start at some random set of weights
- Use forward propagation to make a prediction
- Use backward propagation to calculate the slope of the loss function wrt each weight
- Multiply that slope by the learning rate, and subtract from the current weights
- Keep going with that cycle until we get to a flat part
Stochastic gradient descent¶
- It is common to calclate slopes on only a subset of the data ('batch')
- Use a different batch of data to calculate the next update
- Start over from the beginning once all data is used
- Each time through the training data is called an epoch
- When slopes are calculated on one batch at a time its called stochastic gradient descent
- Note: I guess this is a way to prevent over fitting to a specific 'batch' of training data. Or it could just be used to speed things up.
Building deep learning models with keras¶
Creating a keras model¶
Model building steps¶
- Specify Architecture
- Compile
- Fit
- Predict
keras notes¶
- you need to specify the number of inputs to the first layer. This is the number of features or columns in the data
- We will focus on sequential. This means layers connect only to the next layer. Like what we have practiced in this clas. There are more complex layer formats but this will work for now.
- In a dense layer all of the nodes in the previous layer connect to all the nodes in the current layer.
- Here we use the 'relu' activation function. Keras supports pretty much all activtion functions we would want to use in practice.
Specifying a model¶
file = 'https://assets.datacamp.com/production/course_1975/datasets/hourly_wages.csv'
wages = pd.read_csv(file)
wages.head()
target = wages['wage_per_hour'].values
print(target.shape)
target[0:6]
predictors = wages.drop('wage_per_hour', axis = 1).values
print(predictors.shape)
predictors
# Import necessary modules
import keras
from keras.layers import Dense
from keras.models import Sequential
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
# Set up the model: model
model = Sequential()
# Add the first layer
model.add(Dense(50, activation = 'relu', input_shape = (n_cols,)))
# Add the second layer
model.add(Dense(32, activation = 'relu'))
# Add the output layer
model.add(Dense(1))
Compiling and fitting a model¶
Compile your model¶
- Specify the optimizer
- Controls the learning rate
- Many options and mathematically complex
- Even the experts don't know all the details and options
- "Adam" is ususally a good robust choice
- Loss function
- "mean_squarred_error" is common for regression problems
- we will use something else later for classificaiton problems
Fitting a model¶
- Applying backpropation and gradient descent with your data to update the weights
- This will be similar to what we did in scikitlearn but with more options
- Scaling data before fitting can ease optimization
Compiling the model¶
- documention on "adam" model and others
- original paper on adam model
# Compile the model
model.compile(optimizer = 'adam', loss = 'mean_squared_error')
# Verify that model contains information from compiling
print("Loss function: " + model.loss)
Fitting the model¶
# Fit the model
model.fit(predictors, target)
Classification models¶
Classification¶
- 'categorical_crossentropy' loss function
- Not the only one, but by far the most common
- Similar to log loss: lower to better
- Add metrics = ['accuracy'] to compile step for easy-to-understand diagnostics
Output layer has separate node for each possible outcome and uses 'softmax' activation
- this is ensures the output sums to 1 so they can be interpreted as probabilities
We will have a separate node in the output for each possible class
We will split or results classification into a boolean column for each outcome
- This is called one hot encoding
We use the function
to_categoricalto do the one hot encoding- the instructor likes to load data with pandas so he can inspect it easily. I do too.
- We will drop the target and then convert to a numpy matrix with
to_matrix - Then convert the target data to categorical columns
- After that our model looks the same except we use 2 nodes at the end andit has the softmax activation function
- We will look at better ways to determine how long to train later on.
Understanding your classification data¶
file = 'https://assets.datacamp.com/production/course_1975/datasets/titanic_all_numeric.csv'
titanic = pd.read_csv(file)
titanic.head()
titanic.describe()
Last steps in classification models¶
predictors = titanic.drop('survived', axis = 1).values
predictors
from keras.utils import to_categorical
# Convert the target to categorical: target
target = to_categorical(titanic.survived)
target
titanic.survived.head()
n_cols = predictors.shape[1]
# Import necessary modules
import keras
from keras.layers import Dense
from keras.models import Sequential
# Set up the model
model = Sequential()
# Add the first layer
model.add(Dense(32, activation = 'relu', input_shape = (n_cols,)))
# Add the output layer
model.add(Dense(2, activation = 'softmax'))
# Compile the model
model.compile(
optimizer = 'sgd',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
# Fit the model
model.fit(predictors, target)
- What if I used more layers.
- Just doing a litle practice here
- The example in the slides had more layers and an
adamoptimizer
model = Sequential()
model.add(Dense(100, activation = 'relu', input_shape = (n_cols,)))
model.add(Dense(100, activation = 'relu'))
model.add(Dense(100, activation = 'relu'))
model.add(Dense(2, activation = 'softmax'))
model.compile(
optimizer = 'sgd',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
model.fit(predictors, target)
- Using a thousand nodes in each layer makes it way slower, but it gets more accurate
- Wait how does it test the accuracy? Does it use cross validation?
model = Sequential()
model.add(Dense(1000, activation = 'relu', input_shape = (n_cols,)))
model.add(Dense(1000, activation = 'relu'))
model.add(Dense(1000, activation = 'relu'))
model.add(Dense(2, activation = 'softmax'))
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
model.fit(predictors, target)
Using models¶
Steps¶
- Save the model
- Reload it
- Make predictions with it
Notes¶
- Use the save method and a file name to save the model
- we use hdf5 files to save the model which are .h5 extension
- The predictions result will be in the same format as the target variable (two columns, categorical)
- We just want percent survived here so we take the second column
- I'm using the predictors data that we used to train the model just for the example
- Of course I'd want to use testing data normally
from keras.models import load_model
model.save('model_file.h5')
my_model = load_model('model_file.h5')
predictions = my_model.predict(predictors)
probability_true = predictions[:,1]
probability_true[0:10]
Verifying model structure¶
my_model.summary()
Making predictions¶
- This just repeats what I did above, but this is the full process
- Except I don't have hold out data so I will use the predictors matrix again
# Specify, compile, and fit the model
model = Sequential()
model.add(Dense(32, activation='relu', input_shape = (n_cols,)))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(predictors, target)
# Calculate predictions: predictions
predictions = model.predict(predictors)
# Calculate predicted probability of survival: predicted_prob_true
predicted_prob_true = predictions[:,1]
# print predicted_prob_true
print(predicted_prob_true[:20])
Fine-tuning keras models¶
Understanding model optimization¶
Why optimization is hard¶
- Simultanesously optimixing 1000s of parameters with complex relationships
- The optimum weight for any one weight depends on the values of the other weights and there are a lot of weights
- Updates may not improve model meaningfully
- Updates too small (if learning rate is low) or too large (if learning rate is high)
- Smart optimizers like
adamhelp, but problems can still occur
- Smart optimizers like
Dying neuron problem¶
- Once a node starts always getting negative inputs
- It may continue only getting negative inputs
- Conributes nothing to the model
- "Dead" neuron
Vanishing gradient problem¶
- Occurs when many layers have very small slopes (e.g. due to being on flat par of tanh curve)
- This can happen when using tanh activation funciton. There is no zero slope. But as the values get high the slopes approch zero
- In deep networks, updates to backprop were close to 0
- Research on activation functions is on going
Changing optimization parameters¶
def get_new_model(input_shape):
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = input_shape))
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
return(model)
# Import the SGD optimizer
from keras.optimizers import SGD
# Create list of learning rates: lr_to_test
lr_to_test = [.000001, 0.01, 1]
input_shape = (predictors.shape[1],)
# Loop over learning rates
for lr in lr_to_test:
print('\n\nTesting model with learning rate: %f\n'%lr )
# Build new model to test, unaffected by previous models
model = get_new_model(input_shape)
# Create SGD optimizer with specified learning rate: my_optimizer
my_optimizer = SGD(lr=lr)
# Compile the model
model.compile(
optimizer = my_optimizer,
loss = 'categorical_crossentropy')
# Fit the model
model.fit(predictors, target)
Model validation¶
Validation in deep learning¶
- Commonly use validation split rather than cross-validation
- Deep learning widely used on large datasets
- Single validation score is based on large amount of data, and is reliable
- Repeated training from cross-validation would take long time
Model Validation¶
- You can use
validation_split = 0.3in themodel.fitfunction
Earling Stopping¶
- You can set up an early stopping monitor with a patience.
- The patients is the number of epochs that the model can go withouth improving before it stops
- One epoch is normal, but 2 or 3 is unlikely. If that many epochs go by without improvement the model is uunliekly to turn around and start improving again.
- The early stopping monitor is passed into the
model.fitfunction as a callback. - There are other callbacks we can used when we get more advanced at this.
- Now we can set a higher max epochs because we know our model will stop if it finished early
- we use the
epochs = 20argument
- we use the
Experimentation¶
- Experiment with differnt architectures
- More layers, fewer layers, more nodes, fewer nodes, etc
- A good model requires some experimentation
- We will need to build more intuition on where to experiment
Evaluating model accuracy on validation dataset¶
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
input_shape = (n_cols,)
# Specify the model
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = input_shape))
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
# Compile the model
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Fit the model
hist = model.fit(
predictors, target,
validation_split = 0.3)
Early stopping: Optimizing the optimization¶
# Import EarlyStopping
from keras.callbacks import EarlyStopping
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
input_shape = (n_cols,)
# Specify the model
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = input_shape))
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
# Compile the model
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Define early_stopping_monitor
early_stopping_monitor = EarlyStopping(patience = 2)
# Fit the model
model.fit(
predictors, target,
epochs = 30,
validation_split = 0.3,
callbacks = [early_stopping_monitor])
- This seems a little confusing to me still.
- The
val_lossscore hits .5130. The next 2 epochs are not as good but it does not stop there - Its stops later after one non improving epoch. Seems to make no sense
Experimenting with wider networks¶
# Define early_stopping_monitor
early_stopping_monitor = EarlyStopping(patience=2)
# Create model 1
model_1 = Sequential()
model_1.add(Dense(10, activation='relu', input_shape = input_shape))
model_1.add(Dense(10, activation='relu'))
model_1.add(Dense(2, activation='softmax'))
# Compile model_2
model_1.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Create the new model: model_2
model_2 = Sequential()
model_2.add(Dense(100, activation='relu', input_shape = input_shape))
model_2.add(Dense(100, activation='relu'))
model_2.add(Dense(2, activation='softmax'))
# Compile model_2
model_2.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Fit model_1
model_1_training = model_1.fit(
predictors, target,
epochs=15,
validation_split=0.2,
callbacks=[early_stopping_monitor],
verbose=False)
# Fit model_2
model_2_training = model_2.fit(
predictors, target,
epochs=15,
validation_split=0.2,
callbacks=[early_stopping_monitor],
verbose=False)
# Create the plot
plt.plot(
model_1_training.history['val_loss'], 'r',
model_2_training.history['val_loss'], 'b')
plt.xlabel('Epochs')
plt.ylabel('Validation score')
plt.show()

- The blue model is very different each time I run this code chunk
- It does not seem as stable. It has a tendency to jump up and down
- The red model usually looks fairly similar on each run.
- Some times it actually does better than the blue model which is supposed to be better here.
Adding layers to a network¶
- Now we'll experiment with a deeper network
# The input shape to use in the first hidden layer
input_shape = (n_cols,)
# Create model 1
# Create the new model: model_2
model_1 = Sequential()
model_1.add(Dense(50, activation='relu', input_shape = input_shape))
model_1.add(Dense(50, activation='relu'))
model_1.add(Dense(50, activation='relu'))
model_1.add(Dense(2, activation='softmax'))
# Compile model_1
model_1.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Create the new model: model_2
model_2 = Sequential()
model_2.add(Dense(50, activation='relu', input_shape = input_shape))
model_2.add(Dense(50, activation='relu'))
model_2.add(Dense(50, activation='relu'))
model_2.add(Dense(2, activation='softmax'))
# Compile model_2
model_2.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Fit model 1
model_1_training = model_1.fit(
predictors, target,
epochs=20,
validation_split=0.4,
callbacks=[early_stopping_monitor],
verbose=False)
# Fit model 2
model_2_training = model_2.fit(
predictors, target,
epochs=20,
validation_split=0.4,
callbacks=[early_stopping_monitor],
verbose=False)
# Create the plot
plt.plot(
model_1_training.history['val_loss'], 'r',
model_2_training.history['val_loss'], 'b')
plt.xlabel('Epochs')
plt.ylabel('Validation score')
plt.show()

- This is an interesting example. But again it seems to be a coin flip as to which model is better.
- Also they pth seem to jump up in the validation score sometimes at random.
- I would think the tuning would improve over time steadily
Thinking about model capacity¶
- Its still a little more of an 'art' to tune good deep learning algorithms compared to other types of maching learning algorithms
- Model capacity should be one of the key considerations when considering what models to try
- Model (or network) capacity is closely related to over and under fitting
- Model capicity is our models ability to capture predictive patterns in our data
- Adding more nodoes to a layer or more layers, increases the models capacity
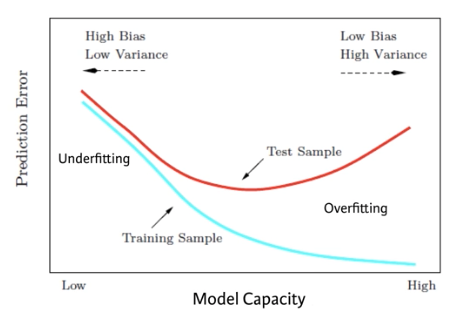
Workflow for optimizing model capacity¶
- Start with a small network
- Gradually increase capacity
- Keep increasing capacity until validation score is no longer improving
- You can back it up a little bit but the model is probably near the ideal
- Here is an example workflow
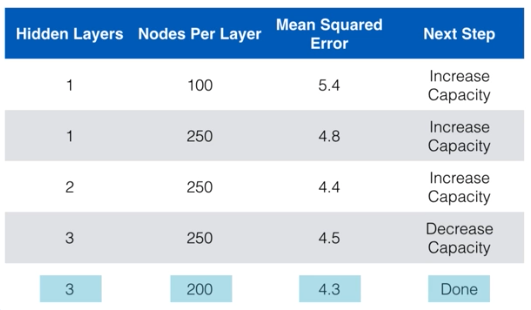
- How should we add capaicty, nodes or layer?
- There is no universal answer to this
- Generally we just want to consider if we are increasing or decreasing capacity
Stepping up to images¶
Recognizin handwritten digits¶
- MNIST dataset
- This is a very popular dataset to get started working with images
- I think we used this in Andrew Ng's machine learning class on coursera
- 28 x 28 grid flattened to 784 values for each image
- Value in each part of array denotes darkness of that pixel 0 - 255
Building your own digit recognition model¶
- We've loaded only 2500 images, rather than 60000 which you will see in some published results.
Deep learning models perform better with more data, however, they also take longer to train, especially when they start becoming more complex.
If you have a computer with a CUDA compatible GPU, you can take advantage of it to improve computation time.
- If you don't have a GPU, no problem! You can set up a deep learning environment in the cloud that can run your models on a GPU.
- Here is a blog post by Dan that explains how to do this - check it out after completing this exercise! It is a great next step as you continue your deep learning journey.
file = 'https://assets.datacamp.com/production/course_1975/datasets/mnist.csv'
digits = pd.read_csv(file)
print(digits.shape)
digits.head()
X = digits.drop('5', axis = 1).values
X
y = to_categorical(digits.iloc[:,0])
y
- I'm actyally just getting around 53% accuracy so I'm going to tweek this a bit
from keras.callbacks import EarlyStopping
n_cols = X.shape[1]
# Create the model: model
model = Sequential()
model.add(Dense(50, activation = 'relu', input_shape = (n_cols,)))
model.add(Dense(50, activation = 'relu'))
model.add(Dense(10, activation = 'softmax'))
# Compile the model
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Fit the model
model_training = model.fit(
X, y,
epochs = 20,
validation_split = 0.3,
callbacks = [EarlyStopping(patience = 3)],
verbose = False)
# Create the plot
plt.plot(model_training.history['val_loss'], 'b')
plt.xlabel('Epochs')
plt.ylabel('Validation score')
plt.show()
plt.plot(model_training.history['val_acc'], 'r')
plt.xlabel('Epochs')
plt.ylabel('Validation Accuracy')
plt.show()


- Well that a little dissappointing
- I was hoping for something in the high nineties
- In the class we get .8893 with what I think is the same data
Final thoughts¶
- The instructor says its just like riding a bike. The hardest part is getting to the point where you can practice on your own. And now we are there
- Start with problems that involve standard prediction problems on tables of numbers
- So like the ones we have seen in previous classes
- I can also use kaggle or other tutorials to see how this will perform
- Then try images (with convolutional neural networks)
- Kaggle is a great place to find datasets to work with
- And there forums are a good place to keep learning as well
- Check this wiki page on data sets for machine learning research
- keras.io has excellent documention
- it also has nice examples
- tensor flow also has some good examples
- We need to set up a computer with GPUs. Get some on amazon.