Technical Challenges
This section considers some of the technical work areas that should be clarified for a more precise and detailed specification of Web Publications. The list is not exhaustive and there are only hints at the technical solutions without claiming to be complete and tested for validity. It must also be emphasized that some of solutions to the problems listed below may not come from W3C, but possibly from other, external organizations (document identification is a typical example).
The section provides some conceptual framework for the technical discussion. The most important definition is the one of Web Publications: the fact that a WP, i.e., a single Web Resource, identifies a collection of Web Resources that conveys the “boundedness” which characterizes a publication (e.g. a book or an article). All technical issues in this section are, fundamentally, around the question on how this boundedness should co-exist with the opennes of the Web in general.

Web Publications
Online/Offline
When handling Web Publications, a user agent has to achieve several tasks:
- Provide some sort of a local storage, or cache, of the WP content. To achieve this, the agent has to catch the HTTP(S) requests stemming from the rendering engine and has to, possibly, serve the content from its cache or the file. In other words, the user agent has to act as a network proxy.
- Take care of the conversion of locators to the consituent resources of a WP, possibly convert from locators provided via state locators or a state independent locator: the differences among these different locators should become transparent to the rendering engine.

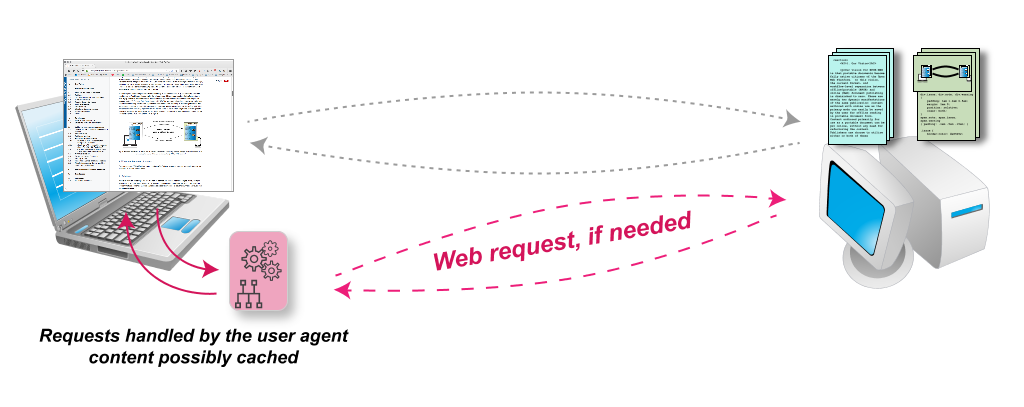
The latest evolution of browser technologies around Web Workers [[web-workers]] and Service Workers [[service-workers]] make the development of such a user agent feasible. Service Workers provide a flexible and programmable way to efficiently implement local caching of Web Resources. Caching is implemented as a programmable network proxy, meaning that the browser’s rendering engine becomes oblivious to whether a resource originates from the local cache or directly from the network: these are indeed some of the basic functionalities a user agent must provide to handle Web Publications.
Addressing and Identification
HTTP(S) URLs serve as the fundamental method for addressing a resource, or a fragment thereof, on the Web. Such URLs can also be used to uniquely identify a resource; however, conceptually, the role of addressing and identification are different. Both of these functionalities should be available for Web Publications: a publication should be uniquely identified for, e.g., library catalogues or archival, and a resource locator should be available so that the user could access the content. In other words, a Web Publication SHOULD have both one or even possibly several identifier(s) and one locator. These may be be identical but may also be different: e.g., an identifier may refer to a specific publication by a publisher (e.g., using an ISBN), whereas the locator may refer to a personal copy of that publication that the owner can freely annotate for personal use.
A typical use case for the presence of an identifier beyond the need for a locator is in academic and scholarly publishing. There are currently several methods for citing online works, but there is no equivalent standard method for citations to ebooks. Even if a reflowable ebook is cited by a scholar, the author must refer to the PDF, paper copy, or HTML version to cite it in her bibliography. Identifiers attached to Web Publications should enable stable citations.
A general [[URI]] (which includes the notion of [[URL]]) MAY serve as an identifier using, e.g., the [[ISBN-URN]] or [[UUID]] schemes. But an identifier does not necessarily resolve to a location on the Web, although it is a good practice to have a dereferencable identifier.
There is no ubiquitously accepted method for identifying a publication among the various document formats (whether electronic or printed). Within the scholarly publishing industry, for example, initiatives such as DOI and CROSSREF have addressed this problem, whereas traditional “trade” publishing rely more on ISBN related services. Some of these identifier schemes provide resolver services or a “standard” representation in term of [[URL]]. The definition of Web Publication should be oblivious to the exact identification used; this issue is left to specialized services and industry organizations. Architecturally, the only requirement, regarding identifiers, is that the complete manifest of a Web Publication MUST include a manifest item for one, or more, identifiers, and that these should be stable across, for example, copying the publication or changing its location on the Web. This document concentrates on addressing only, i.e., on the management of locators.
- A set of identifiers (with possibly a label assigned to each identifier to describe what it is for and who is the authority to assign them)
- A state independent locator (can we call this a 'state independent locator'?)
- State specific locators of a particular copy (ie, a locator to my copy in zip, and a separate locator to the unpacked version on my server)
The rule being that the entries in (1) SHOULD be changed only by the respective authorities, and they MUST be part of the PWP manifest.
WP Manifests
The manifest of Web Publications is a Web Resource that includes information pertaining to the overall publication structure, such as the default logical reading order(s) of the set of resources that comprise the publication (the “spine”), as well as predictable user-facing meta-structures, such as one or several tables of contents, glossaries, etc. The WP manifest may also include various metadata (either directly or via further references) that are essential for the overall publishing workflow. The exact definition of all possible manifest items, the internal structure and serialization syntax of a manifest, etc., will require additional work as part of a more detailed specification of Web Publications.
A fundamental question that must be answered is how does a user agent get hold of the manifest. Because the publication patterns of WPs can be different depending on publishers, authors, etc., there should be different ways of accessing the manifests: it can be referred to via a link element in an HTML file, can be in an agreed-upon-position within a package, or can be conveyed through a LINK header of an HTTP(S) request. The user agent gets hold of the manifest by following a hierarchy of these different possibilities; a separate section in the appendix provides more details. (Note that accessing a manifest also has some security issues; the “Obtaining a manifest” of the “Web App Manifest” [[web-manifest]] document provides some further details that could be adopted, too.)
This algorithm is typically performed by the user agent when initialized with the state independent locator of a particular WP instance.
The “Web App Manifest” [[web-manifest]], currently developed at W3C, is one example of a technology that could be used, or adopted, to define the final formats for PWP manifests. Although the current [[web-manifest]] drafts is geared towards Web Applications, it also includes extension points to define further manifest items necessary for PWP. Some of these extra manifest items have been already explored within the framework of the “Browser Friendly Manifestation” work of the EPUB3.1 Working Group at the IDPF.
Metadata Discovery
Throughout the digital publishing industry, highly specialized metadata vocabularies, and serialization forms thereof, are being used. Within book trade publishing as an example, ONIX [[ONIX]] has attained a dominant status as a metadata package that typically exists (in XML form) independently of the publication, and contains not only bibliographic metadata, but also trade information such as pricing. Scholarly publishing, on the other hand, often uses various derivatives of the ubiquitous BibTeX vocabulary.
While not contradicting the obvious use cases for out-of-line metadata records as used by publishers, retailers and libraries, Web Publications must define a syntax for basic in-line metadata records that is agnostic to the publication’s states. This means that the syntax must seamlessly support discovery and harvesting by both generic Web search engines, as well as dedicated bibliographic/archival/retailer systems. While it is expected that Web Publications will define a minimal set of required metadata (cf. the section ), development and adoption of other vocabularies in Web Publications will most likely be deemed as out of scope. In other words, domain-specific metadata requirements are up to the domains themselves to define via a profiling mechanism, or similar yet-to-be-defined means.
The adoption of HTML as the vehicle for expressing publication-level metadata (i.e., using RDFa [[html-rdfa]] and/or Microdata [[microdata]] for metadata, like authors or title) would have the added benefits of better I18N support than XML or JSON formats.
Web Publication APIs
Access to the specific features of Web Publications via programming API is an important feature when it comes to Web Applicaitons making use of Web Publications.
These APIs would have to be specified through a separate incubation phase. Indeed, their specification requires a different expertise than most of what is described in this document, and for the most part there is no prior art.
Document Collection Interface and API
At the moment, Web Resources used in a Web Publication (e.g., HTML or SVG) can be accessed, programatically, via the Document interface, that provides attributes and methods to access the full tree-like structure of, say, the HTML content, the various attributes on each level, or the textual content. Programs make use of these possibilities, as well as related interfaces, to implement a multitude of operations on a single document.
However, a Web Publication is a collection of documents; consequently, a number of operations are to be performed on that collection as a whole. Typical examples are:
- full text search over the full Web Publication;
- ensure a continuous section, list, table, etc., numbering when the corresponding Web Resources are read continuously, i.e., as part of the Web Publication;
- provide an outlining and/or table of content generation over the Web Publication
Although these operations may be performed via the current standard interfaces, but any such program would have to construct and manage a collection of such document interfaces. It would therefore improve interoperability to define such a Document Collection Interface, together with a set of suitable attributes and methods.
Publication Object Model and API
Many programmatic steps on Web Publications rely on the interplay of the individual resources and information stored elsewhere, for example in the manifest of the Web Publication. These include the creation of the Document Collection Interface object for the Web Publication itself, access to the various metadata items to display, e.g., the titles and other information to the reader, providing information on the publication’s semantic sructure (that may go beyond the structure of the HTML elements in the resources), etc. Furthermore, these information may have to be changed by, e.g., a dynamic editor of a Web Publication.
These operations may be performed individually by, e.g., retrieving the information from the manifest or parsing the metadata that can make use of different syntaxes, it would improve the interoperability of implementations to define a standard Model and API that would represent a Web Publication in all its complexity.
There is, currently, a separate W3C Community Group on Publication Object Models. At this moment no report has yet been published, though.
Styling and Layout, Pagination
As outlined in [[dpub-latinreq]] or [[dpub-css-priorities]], the Open Web Platform in general, and CSS in particular, is still lacking solutions for meeting all of the publishers’ expectations on satisfactory typography and layout for digital publications. While improved presentation fidelity will be of paramount importance to the overall success and adoption rate of Web Publications, it is clear that many of these issues are going to be addressed on a case-by-case basis by the CSS Working Group over a longer period of time. STM publishing, for example, where the faithful representation and rendering of, say, mathematical or chemical formulae is of a paramount importance, has particularly severe requirements that must be fulfilled by the Open Web Platform technologies. Similarly, dynamic pagination of reflowable content is not natively supported by browsers today, and as a result Reading System developers, for example, are forced to implement pagination using various ad-hoc approaches, all coming with a significant penalty in terms of development costs, performance and stability.
It is anticipated that native support for pagination (in CSS and/or in the DOM) is going to be put forward by stakeholders as a critical component of Web Publications; thus the finalization of Web Publications may be contingent on the availability of a native pagination model for Web content.
Note that the “Houdini” Task Force, recently started jointly by the W3C CSS WG and the W3C TAG, may open new avenues to handle pagination.
Presentation Control and Personalization
When reading long-form (and sometimes mission-critical) publications, personalization—i.e., the ability for users to adapt the presentation to suit their needs—is of a great importance. While technologies such as CSS Media Queries have come a long way in terms of adapting content to devices, this is not the same thing as adapting to a user. Presentation control features are often available in e-book readers of different kinds, for example the possibility to dynamically change font size or background/foreground color schemes, but implementations are brittle and limited due to the lack of an underlying framework that explicitly supports user adaptation.
Web Publications needs to incorporate an explicit framework for achieving advanced and predictable user-triggered presentation control. (Note that from this perspective, accessibility can be seen just a radical case of personalization.)
Packaged Web Publications
Archive Formats
Regardless of the details of the practical architecture realizing Web Publications, an archive format is necessary for the storage of a publication as one file (e.g., for distribution or possibly archiving) defined as the packed state of a Packaged Web Publication. A variety of formats for offline/archival storage of collections of digital resources exist today (e.g., [[OCF]], [[ODF]], and [[OOXML]]), but none of them is universally recognized and supported across all ecosystems. Depending on the general architecture, Packaged Web Publications may use one of the deployed formats (e.g., the current EPUB packaging format based on [[OCF]]), or an archive format that is generic and native to the Open Web Platform.
W3C’s Web Platform Working Group has published a Working Draft for a Streamable Package Format for the Web [[web-packaging]] to encompass the needs of various applications (like installing Web Applications or downloading data for local processing). It is not clear at this moment whether browsers will adopt this format, though.
However, the importance of streaming is not paramount for Packaged Web Publications. Indeed, the same publication may be accessed by the same user from different clients; if some user-dependent management also keeps track of the latest reading position in the publication, switching from one client to the other may mean that a client would have to “jump” into the content, thereby bypassing streaming. Nevertheless, if browsers, eventually, do converge towards a browser and streaming friendly packaging format, adopting it for Packaged Web Publications may become a real alternative. The community will have to balance native browser availability against the the wide availibility of tooling and industry distribution based on [[OCF]].
The IETF has published an informational draft on a top-level media type for archives. Although that draft does not specify a specific archive format, and the work is currently on hold, it shows the overall interest in packaging on the Web in line with the concerns of Packaged Web Publications.
Canonical Locators Mapping in user agents
A PWP is published on the server. This PWP includes, e.g., the resource for an image, and is published in at least one of the different states:
- Simply on the Web. The “top level” of this state is available, say, through the URL
https://example.org/books/1/: in this setup, the URL of the image is, say,https://example.org/books/1/img/mona_lisa.jpg. This is the absolute locator of the image in this state. - In a package. This is available through the URL, say,
https://example.org/packed-books/1/package.zip. This is the absolute locator of the PWP in this state, and the locator for the image depends on the structure of the package format.
The published PWP is also assigned a state independent locator, e.g., the URL https://example.org/published-books/1. Reflecting the unpacked state in terms of (file) structure the state independent locator of the same image is https://example.org/published-books/1/img/mona_lisa.jpg.
To ensure the smooth transtion among states the user agent must ensure a smooth transition among the different locators of any resource within a PWP (the image file in this example).
From a user/author point of view, whenever possible, the state independent locator should be used when referring to the PWP in, e.g., annotations. This is also true for URL-s derived from the state independent locator, like https://example.org/published-books/1/img/mona_lisa.jpg. This means the addressing unequivocal; however, a user agent must be prepared for the more general case.
In view of the above, the functionalities of the user agent can be divided into two steps:
- finding, based on the state independent locator, the right values of the various state locators
- extract, based on a specific state locator, the exact locators for additional, internal resources
This functionality is based on the requirement that the complete manifest of a PWP MUST include both the state independent locator as well as all available state locators. Consequently, in order to retrieve the state locators, the PWP must first retrieve the PWP manifest using the state independent locator. (See the separate section on the details of the complete manifest retrieval.) Once the complete manifest is available a resource within a PWP can be retrieved by first deriving the relative locator for a resource (e.g., img/mona_lisa.jpg) and then combining it with the absolute locator corresponding to the state of the PWP as referred to by the rendering engine.
There may be “smarter” user agents that make use of local facilities like caching, but those do not modify these conceptual approaches.
Security Models
The security model of the Web, based primarily on the same-origin policy and the concept of “site”, does not apply to portable documents, as the notion of “origin” is based on HTTP properties that are invalidated/non-existent when a document transitions from its online state to the portable state. (Packaged) Web Publications must incorporate a state agnostic security model that defines rules for both the online and portable states.
