The Problem:
- Statement
- Expected Output
- Architectural Design
Under the Guidance of,
Dr. Ronojoy Adhikari, Institute of Mathematical Sciences, Chennai.
The Problem:
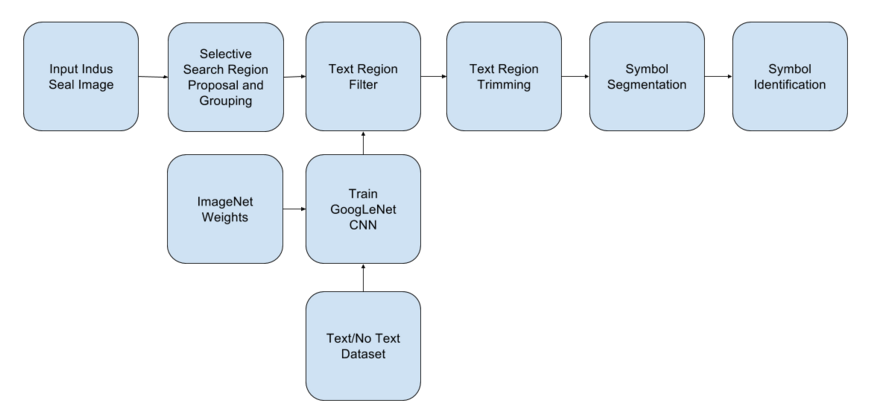
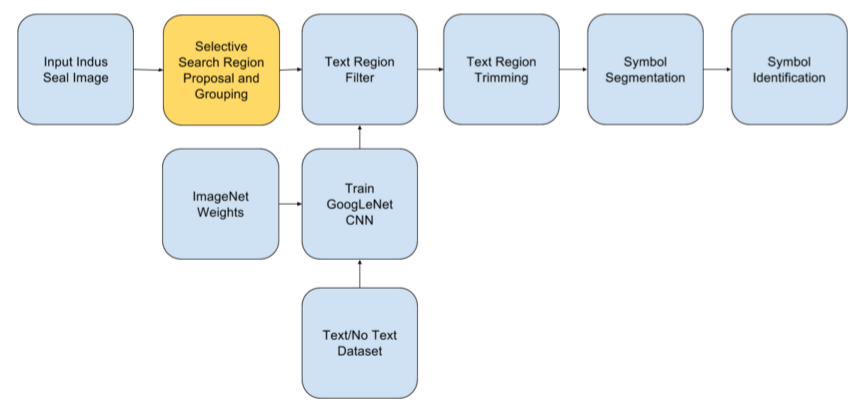
Methodology:
The Results:
Future Prospects:
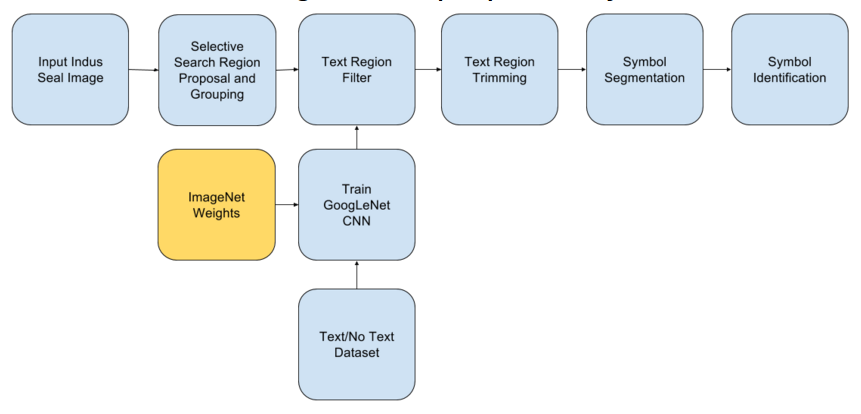
To automatically locate text patches/regions, segment individual symbols/characters from those regions and also identify each symbol/character belonging to the Indus Script, given images of Indus seals from archaeological sites, using image processing and machine learning techniques.
Given Indus seal images, we intend to extract the text sequences as shown below (mapping to the corresponding symbol numbers in the M77 Corpus),
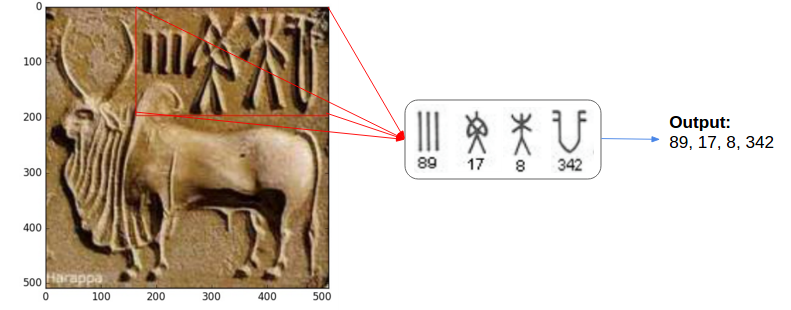
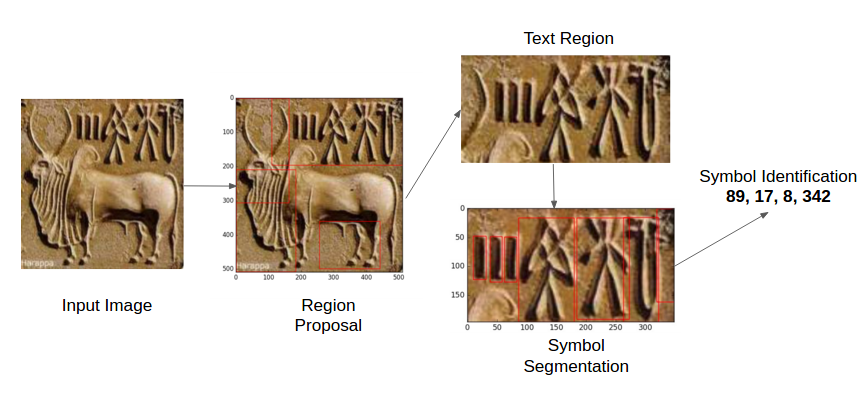
Search terms used: ["indus seals", "harappan seals", "harappan pashupati seal", "harappan unicorn seal", "indus inscriptions", "harappan seals wikipedia", "indus seals and inscriptions", "indus seal stones", "seal impressions indus valley civilization", "indus valley tiger seals", "indus valley seals yoga", "indus valley seals for kids" ]
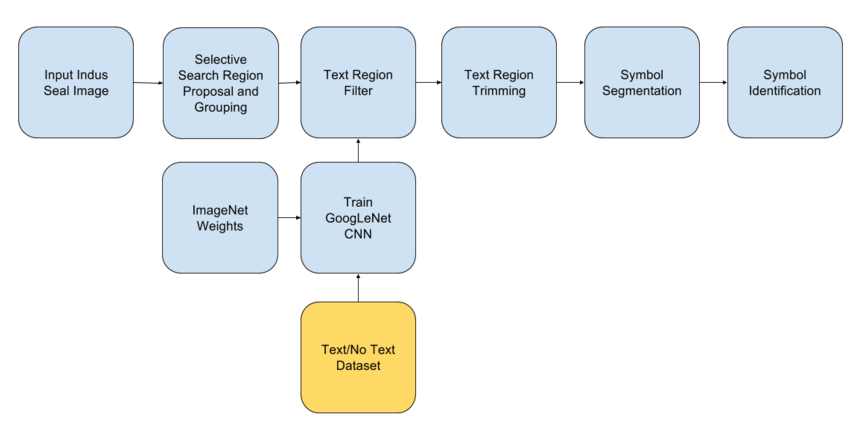
Removed noisy images manually and got 350 useful images out of the 1000 images downloaded, this dataset is refered to as the, “crawled dataset”.

This was formulated by running the selective search algorithm for region proposal (discussed in the upcoming slides) over the 350 seal images from the “crawled dataset” and then manually grouping the resulting 872 regions into those containing, not containing and partly containing the Indus text, to be used by the “Text/No Text Classifier” (discussed in upcoming slides).

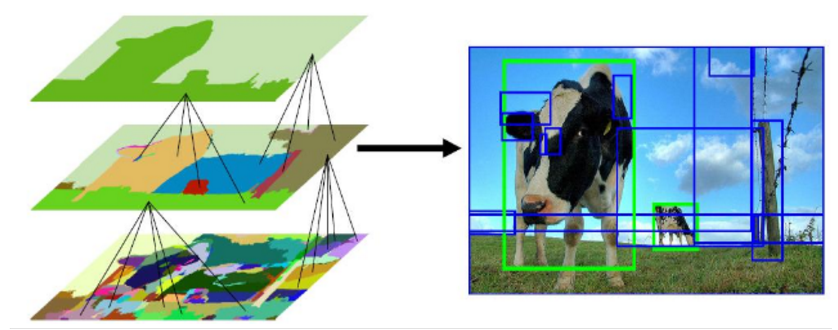
In order to improve the region proposals to suit the purpose of identifying text regions in seal images, a greedy grid search approach over 4 parameters was performed to identify the best combination for a 512x512 image
Once these parameters were fine tuned the regions proposed were relevant enough but were really high in number. Also they were mostly approximations and generalizations of each other.

In order to reduce the number of regions proposed and to increase the quality of the region proposals the following hierarchical grouping methods were devised, (These were applied on images scaled to 512x512 or 256x256 or original size):
Merge Concentric Proposals: Most of the proposals were focusing on the same object with just small variations in the position and area being covered. Such proposals were merged together and replaced by the mean rectangle of all the concentric proposals
Contained Boxes Removal: Some other proposals were subsets of overall text regions, some fraction of each symbols within a text region was also proposed along with the full text region. So, all of these subsets were removed and only the overall proposals were retained
Draw Super Box: Other proposals were overlapping each other such that a single symbol or text region was proposed as two different overlapping regions. The percentage overlap of such proposals was calculated and thresholded at 20 percent, all those pairs of regions having more than 20 percent overlap were replaced by a single minimal super box that bounded both the proposals
Draw Extended Super Box: The regions in hand now were continuous subtext regions in the seal, arranged along the horizontal or vertical axes of the image. As all the subtext regions along the same axis belonged to a piece of text normally, all these were replaced by a single horizontal/vertical super box
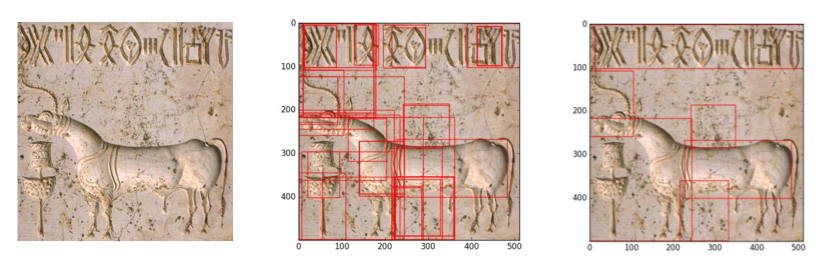
From the results of our region proposal mechanism discussed above, it is clear that the final region proposals have both text and nontext regions being proposed, sometimes a single region proposal might even have both text and non text portions in it. In order to filter these proposals, a CNN image classifier is going to be trained, which will facilitate the region filtering and trimming
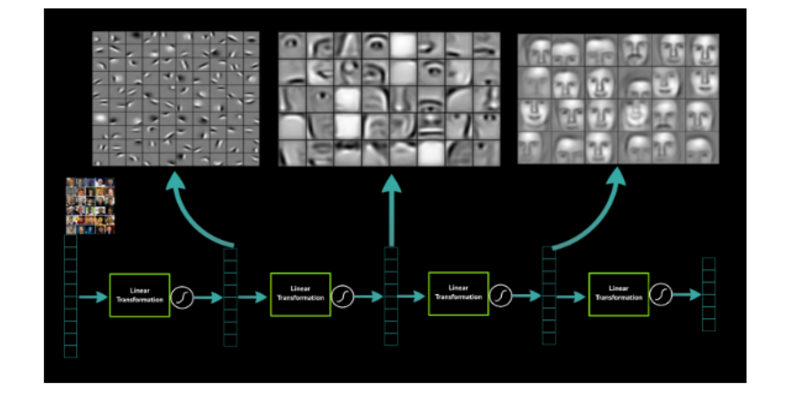
Generally, the way images are vectorized into features has always been hand crafted, but now with increasing problem complexity these deep learnt features are capable of adapting themselves on focusing about, what to look in the images given the requirements, instead of hand-crafting it. With just minimal or no pre-processing, a hierarchy of features can be learnt and with less effort.
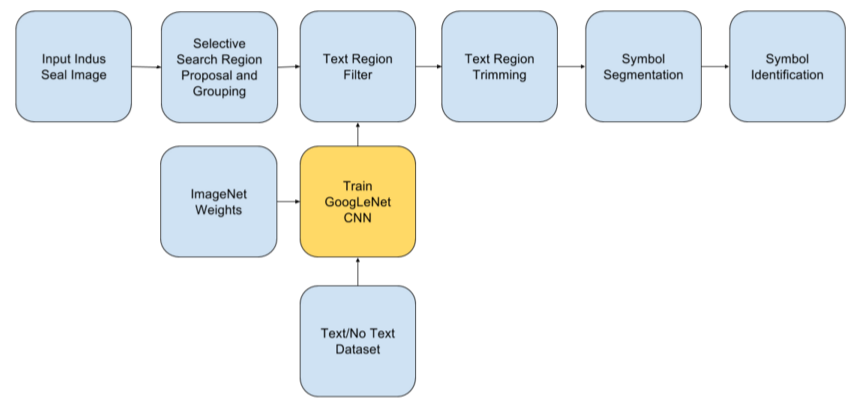
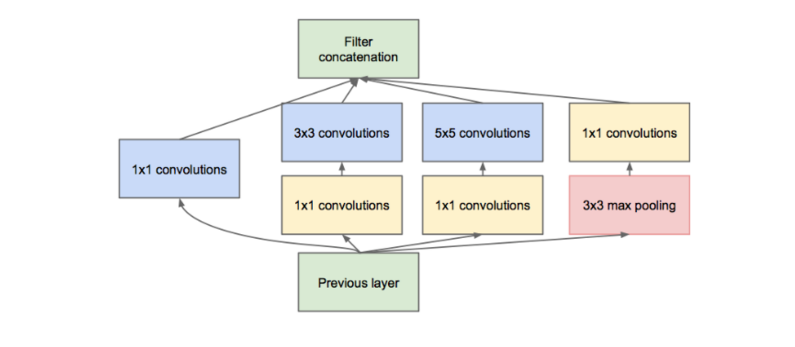
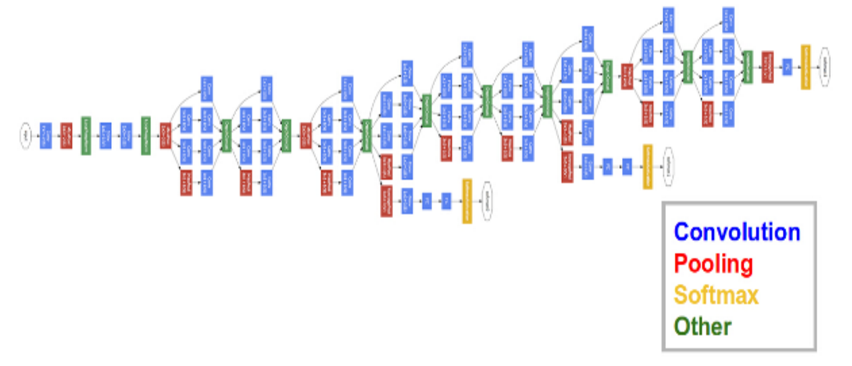
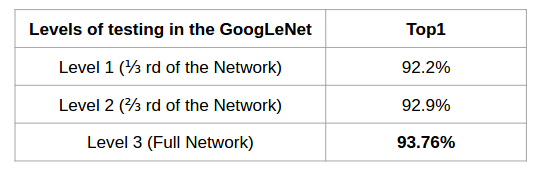
This gave a model with a recall of 93.76%, for text/no text classification of the ROIs
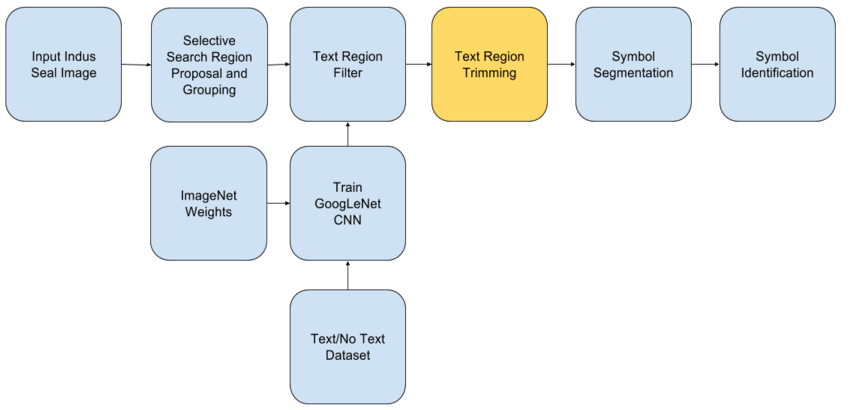
After getting the region proposals from selective search and their labels (Text, No Text and Both) from the Text/No Text Classifier, the following two methods were applied to generate much more accurate and crisp text regions.

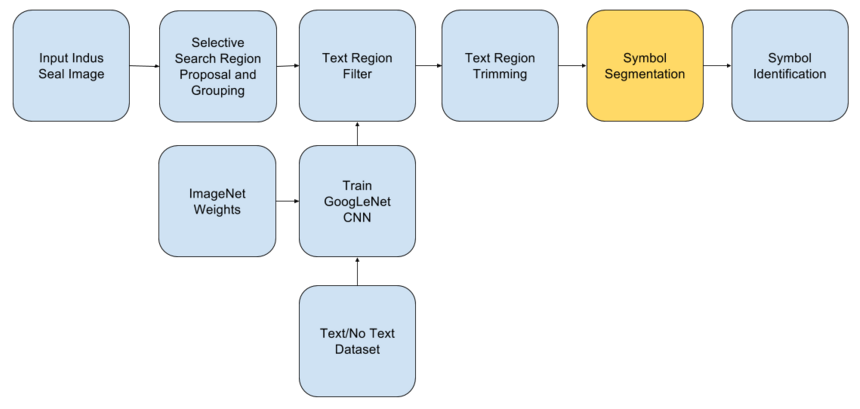
Once we have the text regions, we need to segment out the characters/symbols, for that purpose the selective search algorithm was not effective, So, a customized algorithm that involved the the following steps was used to get the individual symbols out of the text regions,
continued...
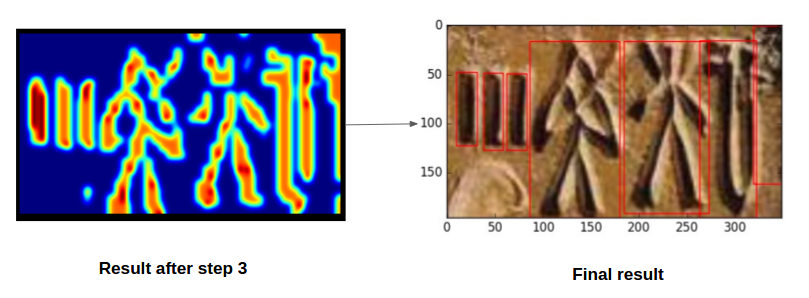
continued...


The symbol extraction pipeline has some drawbacks in terms of performance, it fails to perfectly extract symbol regions from the indus seal images, due to performance dropout at various stages of the pipeline, let us see where and why are there performance degrades,
continued...
The Jar Sign Dataset: This was formulated by manually classifying the 350 seal images from the “crawled dataset”, into those containing and not containing the Jar sign, to be used by the “Jar sign binary classifier”.

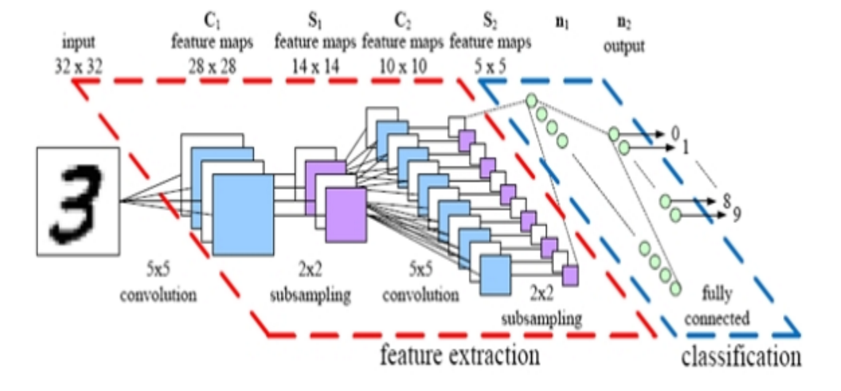
DATA[32x32x3](scaled down by 256) -> Convolution[5x5 Kernel, Stride 1, 20 Outputs] -> Convolution[5x5 Kernel, Stride 1, 50 Outputs] -> Dropout (to prevent over-fitting) -> Fully Connected [500 Outputs] -> ReLU (Non linearity)-> Fully Connected [2 Outputs](2 Classes) -> SoftMax Classifier
Horizontal and vertical flip, Rotation, scaling, translation, Shear, Swirl, Blur, Contrast, Brightness (TO DO)
www Satish Palaniappan
github tpsatish95