NLP with Neural Networks¶
Contents¶
- Introduction to Neural Networks
- Language Models using Neural Networks
- Applications of Word Vectors
- Limitations of Word Vectors
- Getting started...
Introduction to Neural Networks¶
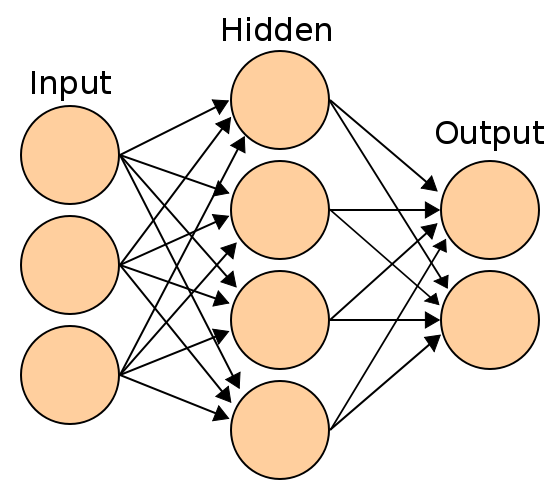
Vectorised Notations¶
Weighted sum of input:
$$ \begin{align} \sum_i w_ix_i &= \left[\begin{matrix} x_1\\ \vdots\\ x_d \end{matrix}\right]^\top \left[\begin{matrix} w_1\\ \vdots\\ w_d \end{matrix}\right] ,& \left[\begin{matrix} x_1\\ \vdots\\ x_d \end{matrix}\right]^\top \left[\begin{matrix} w_{1,1} & \cdots & w_{1,d'}\\ \vdots & \ddots & \vdots\\ w_{d,1} & \cdots & w_{d,d'} \end{matrix}\right] \end{align} = \left[\begin{matrix} \sum_i w_{i,1}x_i & \cdots & \sum_i w_{i,d'}x_i \end{matrix} \right] $$Applying functions to matrices:
$$ f\left(\left[\begin{matrix} r_{0,0} & \cdots & r_{0,d}\\ &\vdots& \\ r_{|D|,0} & \cdots & r_{|D|,d} \end{matrix}\right]\right) = \left[\begin{matrix} f(r_{0,0}) & \cdots & f(r_{0,d})\\ &\vdots& \\ f(r_{|D|,0}) & \cdots & f(r_{|D|,d}) \end{matrix}\right] $$Logistic Regression / Perceptron / Single-layer Neural Network¶
Sigmoid function for binary classification:
$$f(x) = \frac{1}{1-e^{-x ^\top W}}$$Softmax if more than one label:
$$ \frac{1}{ \sum_{j=1}^{L}{e^{ x ^\top W_j }} } \begin{bmatrix} e^{ x ^\top W_1 } \\ e^{ x ^\top W_2 } \\ \vdots \\ e^{ x ^\top W_L } \\ \end{bmatrix} $$To optimise, log-loss function:
$$E(X,y) = - \frac{1}{n} \left[\sum_{i=1}^n y_i \log(f(X_i)) + (1 - y_i) \log(1 - f(X_i))\right]$$Backpropagation¶
Backpropagation is gradient descent performed on the entire neural network function.
Since the neural network is composed of other neural networks, backprop is applying differentiation using the chain-rule recursively. As an example:
$$ \begin{align} l_0 &= d\cdot x\\ l_1 &= b \cdot g(l_0) + c \cdot h(l_0)\\ y &= a \cdot f(l_1) \end{align} $$Once the gradients are computed, it's just the usual gradient descent step:
$$w_i \leftarrow w_i - \varepsilon \Delta w_i$$Language Models using Neural Networks¶
Language model - Probability of a sequence of words in a language:
$$P(w_1,\cdots,w_N)$$Approximation using a $k$-sized window:
$$P(w_1,\cdots,w_N) \approx \prod_{i=1}^{N} P(w_t|w_{t-1},w_{t-2},\dots,w_{t-k})$$We can create a neural network that takes in the previous $k$ words, and outputs the probabilities of all $|V|$ words:
$$P(w_t|w_{t-1},w_{t-2},\dots,w_{t-k}) := f(w_t,w_{t-1},w_{t-2},\dots,w_{t-k})$$Image('images/bengiomodel.png')

Key contributions¶
A mixed model using averaged prediction from this neural net and a trigram beats n-grams using Kneser-Ney backoff,
- with about 24% improvement on Brown corpus and
- 8% on AP news.
Using a table lookup instead of one-hot vectors¶
Using a one-hot vector to represent words allows us to continue using matrix multiplications, but it is equivalent to just extracting a single row out of the word-to-vector table.
$$ \left[\begin{matrix} 0 \\ \vdots \\ 1 \\ \vdots\\ 0 \end{matrix} \right]^{\top} \underbrace{\left[\begin{matrix} r_{0,0} & \cdots & r_{0,d}\\ &\vdots& \\ r_{i,0} & \cdots & r_{i,d} \\ &\vdots&\\ r_{|V|,0} & \cdots & r_{|V|,d} \end{matrix} \right]}_{C} = \left[r_{i,0} ~~ \cdots ~~ r_{i,d}\right] = C_i $$In a bag-of-words model, the input is no longer one-hot, but the same principle applies: just lookup the words in the bag and sum up their vectors
$$ \left[\begin{matrix} 0 \\ \vdots \\ 1 \\ \vdots\\ 1\\ \vdots\\ 0 \end{matrix} \right]^{\top} \underbrace{\left[\begin{matrix} r_{0,0} & \cdots & r_{0,d}\\ &\vdots& \\ r_{i,0} & \cdots & r_{i,d} \\ &\vdots&\\ r_{j,0} & \cdots & r_{j,d} \\ &\vdots&\\ r_{|V|,0} & \cdots & r_{|V|,d} \end{matrix} \right]}_{C} = \left[r_{i,0} + r_{j,0} ~~ \cdots ~~ r_{i,d} + r_{j,d}\right] = C_i + C_j $$Essential thing to remember is that the matrix $C$ is a parameter to be tuned as well.
Image('images/mikolovmodel.png')

Use the hidden layer at $t-1$ as input to the network.
Key contributions¶
Using recurrent connections as context/history instead of using windows of tokens.
Achieved 10.4% improvement for UPenn corpus over KN5 when predictions are averaged with other models.
Backpropagation through time¶
BPTT works the same way as if each of the time steps were a separate layer.
It is equivalent to treating each $w$ as a separate parameter ($w = w_0 = w_1 = \ldots$), and then calculating gradients separately.
Knowing this, we can actually update parameters as we backpropagate through time since $\Delta w = \sum_i \Delta w_i$
Word representation properties¶
Code for the project released on Google code
Trains data on some Wikipedia data, and then allows you to look at a word's neighbours in the vector space
Image('images/wordvec.png')

Key contributions¶
Using neural networks for multi-task NLP learning: POS tagging, chunking, NER, semantic-role labeling and language models. Allow initial layers / word representations to generalise better for other tasks.
Computing final softmax layer in output layer is time consuming. We need to compute scores for all words in the vocabulary
$$ \frac{1}{ \sum_{j=1}^{L}{e^{ x ^\top W_j }} } \begin{bmatrix} e^{ x ^\top W_1 } \\ e^{ x ^\top W_2 } \\ \vdots \\ e^{ x ^\top W_L } \\ \end{bmatrix} $$Collobert & Weston's language model uses a neural network that looks at a fixed n-gram $s$ and outputs a score.
Substitute a random word into the n-gram and insist that it's score be at least 1 lower than the correct n-gram.
Cost function they optimise is a ranking-type cost:
$$\sum_{s \in S} \sum_{w \in W} \max(0,1-f(s)+f(s^w))$$Sampling random words will reduce the need for computing for every word in the vocabulary.
Applications of Word Vectors¶
Recursive Autoencoders¶
An autoencoder is essentially an identity function: It's purpose is to produce it's input in the output layer.
A toy example would be to take in a one-hot vector of 8, and reproduce it in the output. If we allow only 3 units in the hidden layer, the network will find the appropriate representation.

import autoencoder
autoencoder.run_experiment()

Auto-encoders over sequences/structures¶
Minimise the errors between reproduced versions of the current input and the previous hidden-state
Image(url="http://blog.wtf.sg/wp-content/uploads/2014/05/autoencoder.png")

Using additional grammar information, combining the words according to the parse tree
Image(url="http://blog.wtf.sg/wp-content/uploads/2014/05/Screenshot-from-2014-05-10-041050.png")

Image("images/mtrans.png")

Assumption is that word vectors in Spanish are a linear transformation away from their English counterparts
First we train English and Spanish word representations
Since we know some word pairings: ("one","uno"), etc.
We insist that vector for those English words after multiplying with a matrix $W$ (what we'll optimise) is not too far from vector for the corresponding Spanish word.
$$E = \sum_i ||x_i^{\top}W - z_i||^2$$Limitations of Word Vectors¶
The word vectors trained this way are useful, but it greatly depends on the task they're being used for.
At Semantics3 we need to match products across different sites, each with slightly different variations in their names:
iPhone 5 Black
iPhone Five Blk
i Phone 5 Bk
The problem with trying to use the vectors pretrained from the word2vec project is that the words 'white' and 'black' would be really close in the vector space, because they would be in very similar contexts.
This task requires us to be able to say that these are very different, but yet, to know that 'five' and '5' are the same, and 'i' + 'Phone' and 'iPhone' are the same.
Product Name Equivalency model¶
Take 2 names, extract the vectors for each of the tokens, sum and average each one, and then insist that the dot product passed through the sigmoid function gives a 1
$$v(w_1,\cdots,w_n) = \frac{1}{n} \sum_{i=1}^{n} C(w_i)$$$$P((w_1,\cdots,w_n) = (w_1,\cdots,w_m)) := \sigma(v(w_1,\cdots,w_n)\cdot v(w_1,\cdots,w_m))$$So after some training...
Image("images/equivmodel.png")

Getting started...¶
Theano is a good library to get started with.
You create mathematical expressions which need to be compiled, and will then be optimised and translated to native or GPU code.
import theano
import theano.tensor as T
x = T.scalar('x')
squared = x**2
f = theano.function(inputs=[x],outputs=squared)
f(5)
Automatic Differentiation¶
With more complicated models these days, differentiation by hand might be error-prone. Since input is an expression tree, Theano can do the differentiation for you.
gradient = T.grad(squared,wrt=x)
f_prime = theano.function(inputs=[x],outputs=gradient)
f_prime(5)
For an idea of how it works, we can take a look at SymPy
from sympy import *
init_printing()
z = Symbol('z')
f = z**2 + 3*z - 5
f
diff(f,wrt=z)
If you're already used to vectorising your code and working with MATLAB or numpy arrays, it isn't too hard to get started.
Ideas going forward..¶
- Distributed word representations are useful, could explore ways of combining them like the RAE.
- Extracting semantic meaning from combined sentences/phrases.
- Successfully reconstructing sentence from sentence vector (applications in full sentence translation?)
- Kaggle NLP Challenge: Billion Word Imputation