
REST is buzzword & JSON is ubiquitously present. Are we good at parsing? What about huge JSON array? Can we efficiently enumerate on JSON array? Or use parallel producer-consumer? Can we do it in single line?
<< Previous Article (Lets Shake Hands) |
Next Article (Meet Parallel Producers/Consumers) >> |
In DevFast - Lets Shake Hands, we started with some basic, yet powerful, set of extension methods. Those are powerful in following sense:
In summary, following was bundled together (more on WIKI and Releases):
string parsing methods (bool as success indicator with parsed value in out variable)string parsing methods (either parsed value is returned or the given default)Exception when parsing fails)null values etc)bool, string, IEquatable, IComparable, ICollection, Dictionary etc)async / non-async methods for Base64 to/fro conversionsasync / non-async methods for other kinds of Crypto transformation.We all know (or getting to know) that technology is changing fast. Everyone talking about RESTful APIs. XML fading and JSON is emerging as a standard format of data exchange over web due to its less verbose light-weight nature and immediate integration with client side scripting. Even in its RAW format, it can be easily understood and manipulated by hand. Moreover, there exist even document oriented databases based on JSON format.
Nonetheless, purpose of this article is neither to explain JSON format nor technologies based on it. Here we are going to talk about how to write succinct & efficient code for JSON operations (serialization/deserialization) and how DevFast can help you do that right!
All the performance statistics are collected on a Windows Machine with following configuration:
Useful links:
As of today, Newtonsoft.JSON (a.k.a. Json.NET) is one of the most performing JSON (De)serialization libraries available. Among many of its useful features, the most commonly used methods are:
Static Methods:
JsonConvert.SerializeObject(dotNetObject)
JsonConvert.DeserializeObject(jsonString)
Instance Methods:
new JsonSerializer().Serialize(writer)
new JsonSerializer().Deserialize(reader)
DevFast takes advantages of these instance methods and proposes following JSON operations as extension methods:
Serialization Methods:
string ToJson<T>(this T source, ...)
void ToJson<T>(this T source, StringBuilder target, ...)
void ToJson<T>(this T source, Stream target, ...)
void ToJson<T>(this T source, TextWriter target, ...)
void ToJson<T>(this T source, JsonWriter target, ...)
Deserialization Methods:
T FromJson<T>(this StringBuilder source, ...)
T FromJson<T>(this string source, ...)
T FromJson<T>(this Stream source, ...)
T FromJson<T>(this TextReader source, ...)
T FromJson<T>(this JsonReader source, ...)
Perhaps, C# Garbage Collection (GC) offers extreme performance but it is also true that NO GC is better than any GC. Talking about Json.NET, the static methods, JsonConvert.SerializeObject(...) and JsonConvert.DeserializeObject(...), are all good: succinct and up to the mark. Unfortunately, there are times when, having knowledge about our objects, we require more control, like passing own instance of StringBuilder in order to recover serialized JSON string, reusing those costly StringBuilders by avoiding GC cycles, allocation of arrays. Lets consider both methods and identify where DevFast can really help you with its single-liners.
StringBuilder, we coin, ToJson<T>(this T source, StringBuilder target, ...), extension method.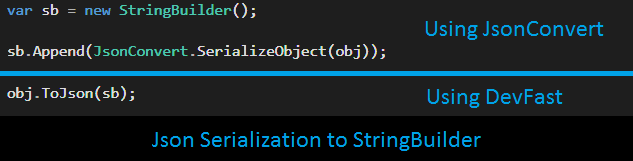
Lets consider some objects of varying sizes to obtain something substantial. Following are sampled statistics (source code):
| ArrayLen | StringLen | Iterations | JsonConvert Time | DevFast Time | Remarks | |
|---|---|---|---|---|---|---|
| SmallObj | - | 58 | 10M | 8545 ms | 8588 ms | DevFast 0.49% slower |
| LargeObj | - | 3976 | 1M | 8413 ms | 7837 ms | DevFast 6.83% faster |
| LargeObj Array | 1K | 4072449 | 1K | 12278 ms | 10348 ms | DevFast 15.71% faster |
Stream. This stream can be network stream, memory stream, file stream or something else. Again, we need some control on the serialization and thus, falls the burden to write the code. And what can be better than a single-line code. Thus, the need of, ToJson<T>(this T source, Stream target, ...), extension method.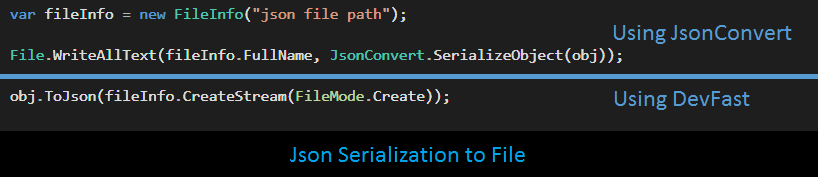
Lets consider again, the above three (3) differently sized objects in conjuction with FileStream this time. Following are sampled statistics (source code):
| ArrayLen | FileSize | Iterations | JsonConvert Time* | DevFast Time* | Remarks | |
|---|---|---|---|---|---|---|
| SmallObj | - | 58 B | 32K | 4351 ms | 3888 ms | DevFast 10.26% faster |
| LargeObj | - | 3985 B | 32K | 4226 ms | 5023 ms | DevFast 18.84% slower |
| LargeObj Array | 1K | 4081665 B | 128 | 2676 ms | 1794 ms | DevFast 32.96% faster |
*Inclusive of File opening/closing time.
MemoryStream instead, in order to collect performance statistics, to perform the same round of tests. We obtained following set of sampled statistics (source code):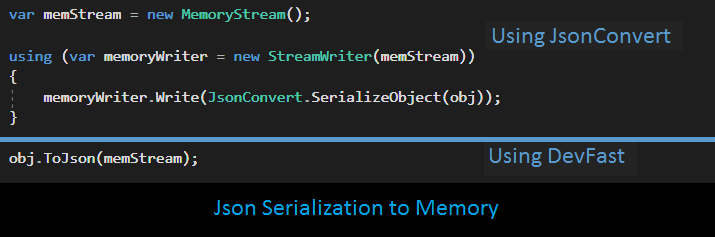
| ArrayLen | FileSize | Iterations | JsonConvert Time | DevFast Time | Remarks | |
|---|---|---|---|---|---|---|
| SmallObj | - | 61 B | 128K | 169 ms | 168 ms | DevFast 0.56% faster |
| LargeObj | - | 3988 B | 128K | 1554 ms | 1342 ms | DevFast 13.64% faster |
| LargeObj Array | 1K | 4081668 B | 256 | 4423 ms | 3073 ms | DevFast 30.51% faster |
StringBuilder.ToString(), before deserialization can take place; we have obtained, FromJson<T>(this StringBuilder source, ...) extension method. If we run our object samples, we obtain following sampled statistics (source code):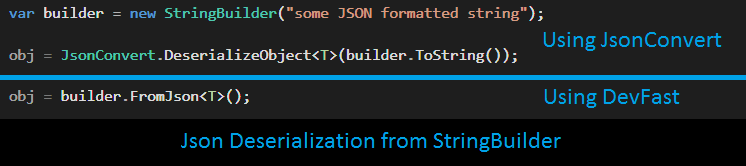
| ArrayLen | StringLen | Iterations | JsonConvert Time | DevFast Time | Remarks | |
|---|---|---|---|---|---|---|
| SmallObj | - | 58 | 2M | 2772 ms | 3051 ms | DevFast 10.06% slower |
| LargeObj | - | 3976 | 512K | 4853 ms | 4680 ms | DevFast 3.56% faster |
| LargeObj Array | 1K | 4072449 | 512 | 6192 ms | 4828 ms | DevFast 22.02% faster |
Stream, we introduce FromJson<T>(this Stream source, ...) extension method. Lets first again run our object samples using FileStream, we obtain following sampled statistics (source code):
| ArrayLen | StringLen | Iterations | JsonConvert Time* | DevFast Time* | Remarks | |
|---|---|---|---|---|---|---|
| SmallObj | - | 58 | 32K | 1362 ms | 1283 ms | DevFast 5.79% faster |
| LargeObj | - | 3976 | 32K | 1899 ms | 1753 ms | DevFast 7.69% faster |
| LargeObj Array | 1K | 4072449 | 128 | 2417 ms | 1893 ms | DevFast 21.66% faster |
*Inclusive of File opening/closing time.
MemoryStream, sampled statistics are as follow (source code):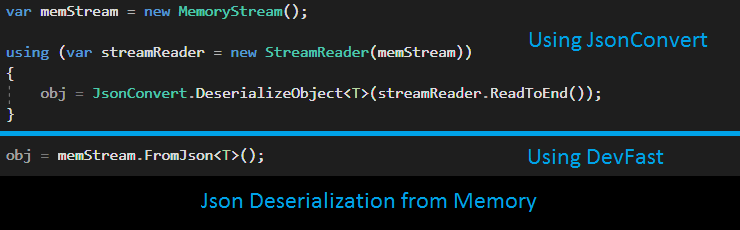
| ArrayLen | StringLen | Iterations | JsonConvert Time | DevFast Time | Remarks | |
|---|---|---|---|---|---|---|
| SmallObj | - | 58 | 1M | 1990 ms | 1846 ms | DevFast 7.22% faster |
| LargeObj | - | 3976 | 256K | 3594 ms | 3048 ms | DevFast 15.18% faster |
| LargeObj Array | 1K | 4072449 | 256 | 4214 ms | 2917 ms | DevFast 30.76% faster |
Most of the times. at client side, using JsonConvert or JsonSerializer for regular (de)serialization hardly makes any difference, specially with modern hardware; as the user hardly perceives those milliseconds of difference. However, this does NOT hold true, specially at, all time busy, server side. Latency aside, memory too becomes one of the major concerns when we deal with JSON Array, especially BIG ones! There are some commonly observed cases, when we deal with these gigantic arrays:
Even on a modest shared server, this can soon result in OutOfMemoryException (OOM), failed/delayed reports etc. In effect, as a quick win, first thought comes to mind is to start creating/receiving smaller size files for processing. At least, this buys some time as OOM are avoided, though, the file count has increased and perhaps some other part of the code became complicated and so as bookkeeping. But hold on! what if we can read those JSON array element one by one? Perform computation in-sync or in-async? What if we can decide how many of those objects should stay in memory at given point in time?
To address these (or similar) requirements, DevFast proposes two (2) approaches to deal with the situation at hands:
IEumerable<T>BlockingCollection<T> to support Parallel Producer-Consumer (PPC)As a first approach, following extension methods are proposed:
Serialization Methods:
string ToJsonArray<T>(this IEnumerable<T> source, ...)
void ToJsonArray<T>(this IEnumerable<T> source, StringBuilder target, ...)
void ToJsonArray<T>(this IEnumerable<T> source, Stream target, ...)
void ToJsonArray<T>(this IEnumerable<T> source, TextWriter target, ...)
void ToJsonArray<T>(this IEnumerable<T> source, JsonWriter target, ...)
Deserialization Methods:
IEnumerable<T> FromJsonAsEnumerable<T>(this StringBuilder source, ...)
IEnumerable<T> FromJsonAsEnumerable<T>(this string source, ...)
IEnumerable<T> FromJsonAsEnumerable<T>(this Stream source, ...)
IEnumerable<T> FromJsonAsEnumerable<T>(this TextReader source, ...)
IEnumerable<T> FromJsonAsEnumerable<T>(this JsonReader source, ...)
Lets quickly see what we gain in terms of memory and/or speed:
| Operation | Peak Memory (JsonConvert Vs DevFast) |
JsonConvert Time | DevFast Time | Remarks | Link |
|---|---|---|---|---|---|
| Serialization*M1 | 2,599,284 K Vs 22,968 K | 7218 ms | 6177 ms | DevFast 14.4% faster | Source Code |
| Deserialization*M2 | 3,092,008 K Vs 23,884 K | 13392 ms | 27331 ms | DevFast 104.08% slower | Source Code |
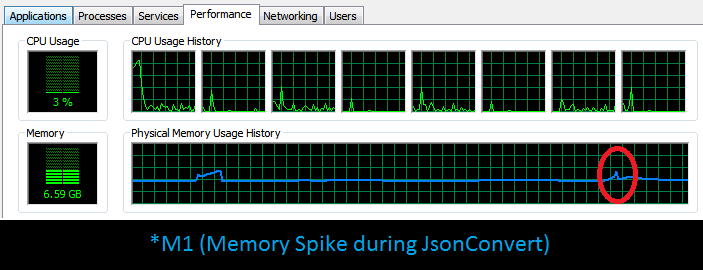
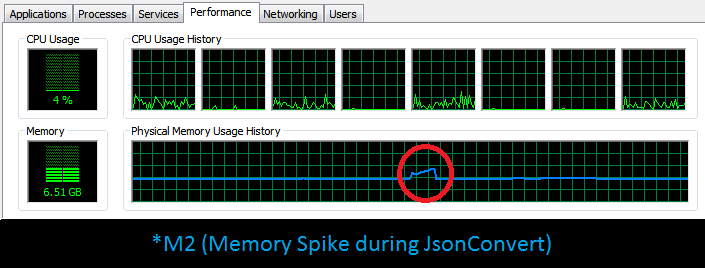
As a matter of fact, IEnumerable approach would keep one object alive per iteration (i.e. elements would be (de)serialized as iterator moves and hopefully GCed on each iteration), thus those noticeable memory gain. Nonetheless, sometimes it might be beneficial to let the (de)serialization in parallel as (producer)consumer. Thus, following set of extension methods is proposed:
Serialization Methods:
string ToJsonArrayParallely<T>(this BlockingCollection<T> source, ...)
void ToJsonArrayParallely<T>(this BlockingCollection<T> source, StringBuilder target, ...)
void ToJsonArrayParallely<T>(this BlockingCollection<T> source, Stream target, ...)
void ToJsonArrayParallely<T>(this BlockingCollection<T> source, TextWriter target, ...)
void ToJsonArrayParallely<T>(this BlockingCollection<T> source, JsonWriter target, ...)
Deserialization Methods:
void FromJsonArrayParallely<T>(this StringBuilder source, BlockingCollection<T> target, ...)
void FromJsonArrayParallely<T>(this string source, BlockingCollection<T> target, ...)
void FromJsonArrayParallely<T>(this Stream source, BlockingCollection<T> target, ...)
void FromJsonArrayParallely<T>(this TextReader source, BlockingCollection<T> target, ...)
void FromJsonArrayParallely<T>(this JsonReader source, BlockingCollection<T> target, ...)
Another feature of such an approach is that we can control the number of objects we would like to keep in transit, during the whole operation, by assigning BoundedCapacity to our BlockingCollection (in other words, controlling memory profile). Lets quickly tabulate sample of memory and speed statistics:
| Operation | Bounded Capacity* | Peak Memory (JsonConvert Vs DevFast) |
DevFast Time | Link |
|---|---|---|---|---|
| Serialization | NONE | 95,736 K | 7105 ms | Source Code |
| 256 | 25,476 K | 8403 ms | ||
| Deserialization | NONE | 26,932 K | 30469 ms | Source Code |
| 256 | 25,020 K | 31134 ms |
*Must be instrumented with sample data, especially when producer is faster than consumer.
As listed above, lets see how we can handle the two (2) cases, JSON file processing & Reporting, using PPC with DevFast.
In order to demostrate the idea, we have (source code):
<film> (normally it contains 1000 rows with 13 columns)SELECT * FROM sakila.film where film_id <= SOME_UPPER_LIMIT and film_id > SOME_LOWER_LIMIT{(0, 100), (100, 200), (200, 300) ... (900, 1000)}BlockingCollectionBlockingCollection)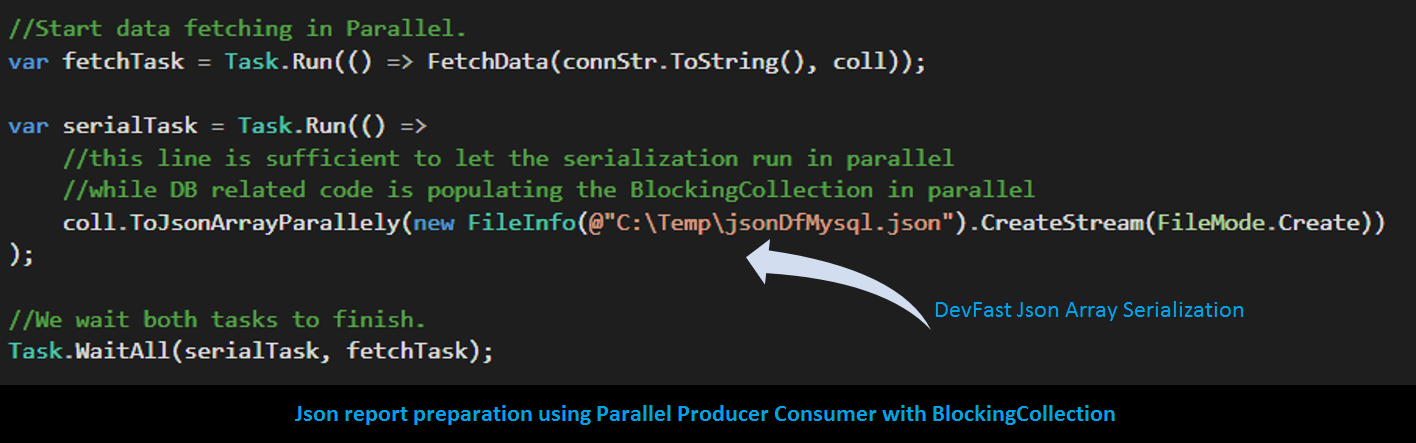
While running sample code we obtain following sampled performance statistics:
In order to demostrate the idea, we have (source code):
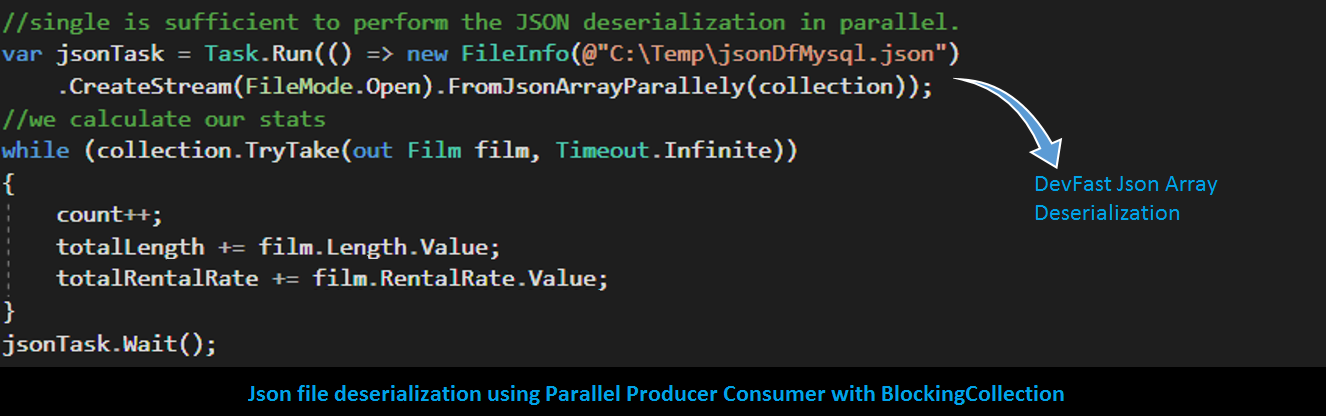
While running sample code we obtain following sampled performance statistics:
Though, the above sample shows a simple PPC pattern of single producer (i.e. deserializer) single consumer (i.e. our dequeuing while loop). Nonetheless, following patterns can also be easily constructed:
C# .Net comes with Deflate & GZip compression out of the box. DevFast takes the advantage over the fact and proposes following extension methods:
Compression Methods:
Task CompressAsync(this ArraySegment<byte> source, Stream target, ...)
Task CompressAsync(this byte[] source, Stream target, ...)
Task CompressAsync(this Stream source, Stream target, ...)
Task CompressAsync(this StringBuilder source, Stream target, ...)
Task CompressAsync(this string source, Stream target, ...)
Decompression Methods:
Task<string> DecompressAsStringAsync(this Stream source, ...)
Task DecompressAsync(this Stream source, StringBuilder target, ...)
Task DecompressAsync(this Stream source, Stream target, ...)
Task<byte[]> DecompressAsync(this Stream source, ...)
Task<ArraySegment<byte>> DecompressAsSegmentAsync(this Stream source, ...)
Reason behind introducing these extensions on ArraySegment<byte> & StringBuilder is to avoid the extra Array (byte or string) creation/copy operations. As these methods are quite straight forward, we quickly lok at these; so that we can look at something more interesting in the next section. Following snapshot provide a quick look on the usage of these methods:
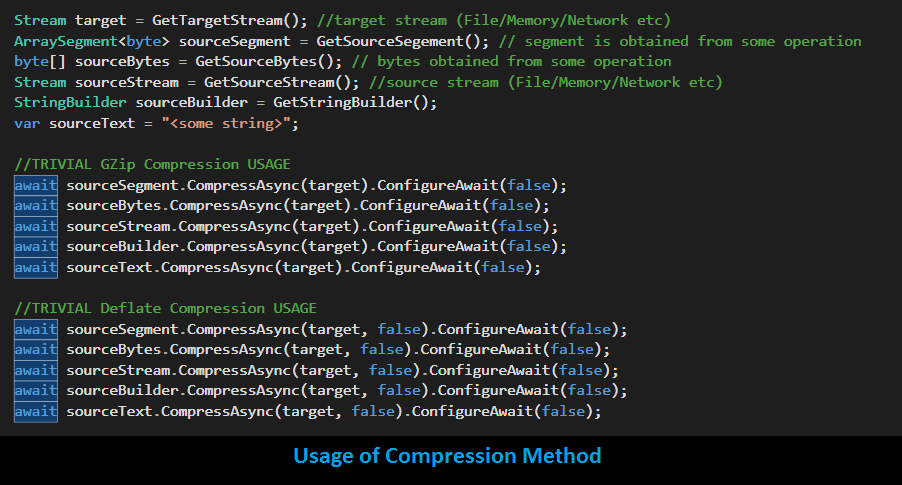
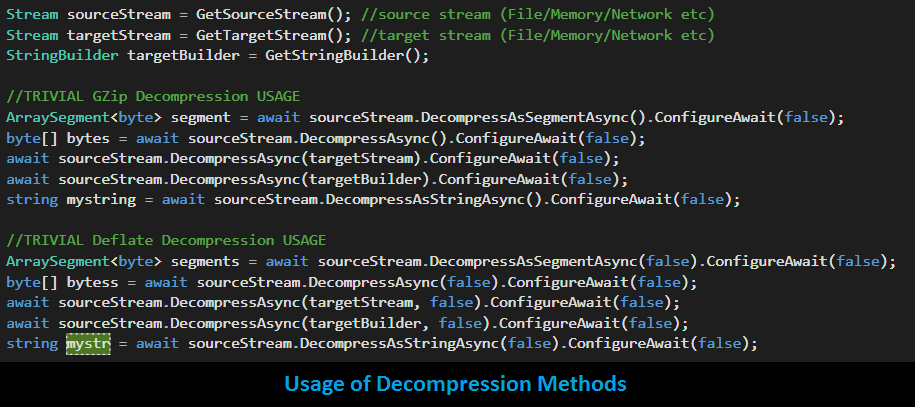
It is true, compression extension methods usage is not rocket science and technically less interesting (yet useful, and who does not love these single liners... haha!). But, moving forward lets think bigger (and better)... afterall, we have introduced all these extensions. We are in a position, now, to exploit the possibility of low-latency pipeline, yet pursue readability with the help of these single-liners. To see it, we must set a non-trivial use case. Lets begin:
Client Story:One fine day, your client asks you to implement a feature with following user-story:
As a user, I would like to have an extract of all the transactions of a given date.
Product Owner Story:Based on user story, product owner, after an apocalyptical introspection/brain-storm, decides to create a new service "TransactionReporting" and claims the budget for the same. Client/PO negotiate on a delivery within 6 months with 100K $ of budget + some regular running feature maintenance budget.
Architect Story:Once budget is sanctioned, PO initiates bilateral talk, with an Architect in confidence, to arrange a solution design, Tech Specs etc. As, WebAPI/
JSONare buzzwords, Architect proposes usingJSONdata exchange in streaming overGET. He also noticed that the byte volume could be high for available bandwidth, thus, suggests compression. Furthermore, due to large number of records, he warns about some significant latency during the database fetch operation (select query), thus, suggest implementation ofPOST(with202response) to acceptDate. And anotherGET(for status monitoring purpose,200and201responses) and a finalGET(to actually recover the file,200response) with GZip compressed JSON file in streaming.(other possibilities: WebHooks, 3rd party Middleware, FTP, shared resource for file exchange etc... Nevermind...)
Team Lead Story:Once design is on the table, Team Lead starts continuous delivery cycle with developers in the team and start creating technical tasks with associated functional & technical specs and sprint planning. So he decides a common multi-layered approach with Presentation/Business/Data Access/Data etc layers.
Developer Story:Based on received functional/tenchnical specs, developer's work reduced to:
- Development of all the tiers
- Unit & Integration Testing
- Performance Testing
Now having all these stories available, we have a better view of the problem. From a developer perspective (from AGILE point of view), we have lot to do under these three (3) major category. Testing (even under TDD), code coverage, improving SONAR KPIs etc demands a lot of efforts and time. And to be truthful, Performance testing (latency, volume, network load etc tests) is procrastinated most of the time until the very end. And if those tests are unsatisfactory... hmmm! God helps the team :)
Anyway, in this given situation, we know that we need to perform performance testing at least at following places:
GET) : Beyond the scope of this article and warrants a separate article; nonetheless, have a look at PushStreamContent and just to begin with create a bogus large text/json file to be transferred from server to client using Get with a Stopwatch.So this section is all about point 3) & 4) and here we will see how DevFast is going to help you out. I urge you to pause reading and think for a while, if it would be you, what would be your solution look like? Also, assume for the moment you do NOT have DevFast package available to you!
In order to understand what we are trying to achieve, it is important we perform the iteration in the same fashion as a developer, who iteratively improves his solution everytime his performance KPIs are in RED, would do! So lets look at following approaches:
We consider following kind-of-pseudocode: (// as comments lines)
//This line is a Memory Black Hole!
//Fetching a small set of record is all OK in this fashion
//but fetching 10's of thousands or millions of records! No way!
//Either you invite OutOfMemory (OOM) exception OR
//you have a HELL lot of RAM installed, do NOT breach
//.Net physical boundaries, do NOT care about GC and so on...
//And in such a case, wts the use of performance testing?
List<TransactionRecord> transactionRecords = dataAccessInstance
.FetchTransactionRecordFor(dateOfTheTransaction);
//Another devil in the corner! Likely to trigger OOM
//or breach Max Object size
var jsonString = JsonConvert.SerializeObject(transactionRecords);
//just need to choose where the file is: on FAR network system,
//or locally?
File.WriteAllText(@"<Full Path Of JSON file>", jsonString);
//After doing all writing, again reading from 1 file and writing to another!!!
//I/O operations are known to be slower! Thus, latency is expected.
//Careful choice of buffersize/compression scheme might be helpful
FileInfo compressedFile = compressionEngine.Compress(@"<Full Path Of JSON file>");
So we have problems with Lists, but thanks to yield return we can iterate over our implementation. We consider following kind-of-pseudocode: (// as comments lines)
//once we have DataReader:
//while(dataReader.Read())
//{
// yield return CreateNewTransactionRecord(dataReader); // usual column to property mapping
//}
using(var fileHandle = CreateFileWriter(@"<Full Path Of JSON file>"))
{
//writing "["
fileHandle.Write(jsonArrayStartToken);
foreach(var obj in dataAccessInstance.FetchTransactionRecordAsEnumerable(dateOfTheTransaction))
{
//writing json string of the object
fileHandle.Write(JsonConvert.SerializeObject(obj));
//writing ","
fileHandle.Write(objectSeparatorToken);
}
//writing "]"
fileHandle.Write(jsonArrayEndToken);
}
//After doing all writing, again reading from 1 file and writing to another!!!
//I/O operations are known to be slower! Thus, latency is expected.
//Careful choice of buffersize/compression scheme might be helpful
FileInfo compressedFile = compressionEngine.Compress(@"<Full Path Of JSON file>");
All looks good for the moment, nonetheless, we notice that while we fetch data from DB we neither do JSON serialization nor do file writing and vice-versa. Furthermore, we also know that both DB operation and File operation are I/O bound, so we must consider Parallel Producer-Consumer (PPC) implementation. Very interstingly, once we are on PPC, we are free to launch many queries in parallel on disjoint partitions of the data.
In order to decouple data fetching from JSON writing lets consider following kind-of-pseudocode: (// as comments lines)
//Inside PopulateTransactionRecordParallel function:
//try
//{
// while(dataReader.Read())
// {
// //Adding objs using usual column to property mapping
// blockingCollection.Add(CreateNewTransactionRecord(dataReader));
// }
//}
//finally
//{
// blockingCollection.CompleteAdding();// mandatory, else consumer will go in infinite sleep (DEADLOCK!)
//}
using(var fileHandle = CreateFileWriter(@"<Full Path Of JSON file>"))
{
var collection = new BlockingCollection();//perhaps with some capacity
var dbtask = Task.Run(() => dataAccessInstance
.PopulateTransactionRecordParallel(dateOfTheTransaction, collection));
//writing "["
fileHandle.Write(jsonArrayStartToken);
foreach(var obj in collection.GetConsumingEnumerable())
{
//writing json string of the object
fileHandle.Write(JsonConvert.SerializeObject(obj));
//writing ","
fileHandle.Write(objectSeparatorToken);
}
//writing "]"
fileHandle.Write(jsonArrayEndToken);
//in case, task throw some error.
await dbtask.ConfigureAwait(false);
}
//After doing all writing, again reading from 1 file and writing to another!!!
//I/O operations are known to be slower! Thus, latency is expected.
//Careful choice of buffersize/compression scheme might be helpful
FileInfo compressedFile = compressionEngine.Compress(@"<Full Path Of JSON file>");
All looks good for the moment, nonetheless, we notice that there are other places where we can improve performance, for example:
This is where DevFast will pitch-in to help you (of course, with its single liners!!!). But before, we begin we need to, again, assume few things:
Lets see how using DevFast library we can re-write Approach 2 and Approach 3 and generate some sample statistics:
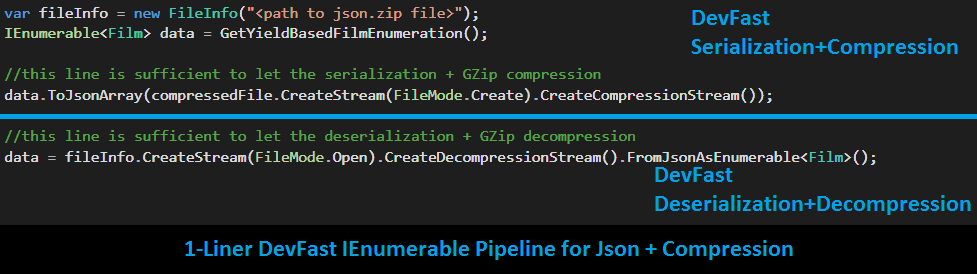
| Operation | Approach 2 Time |
Approach 4 (DevFast) Time |
Peak Memory Bytes |
Remarks | Link | |
|---|---|---|---|---|---|---|
| (Total Records = 1M, Uncompressed JSON File = 337,569,004 Bytes, GZip Compression) | ||||||
| Serialization | 33930 ms | 24865 ms | 42,172 K | DevFast is 26.71% faster |
Source Code | |
| Deserialization2 | - | 13491 ms3 | 24,932 K3 | - | ||
1Must be instrumented with sample data, especially when producer is faster than consumer.
2For Approach 2, no mechanism is known to fetch data as IEnumerable without Memory pressure! For DevFast only Compression & Looping considered (DB operations left for readers)
3Fast consumer effect (counting loop is faster than deserialization). This time can be viewed as pure Enumerable Pipeline Horsepower (Deserialization+Decompression time)
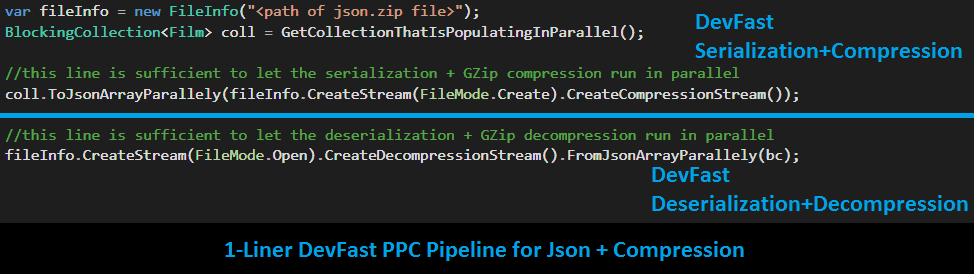
| Operation | Bounded Capacity1 | Approach 3 Time |
Approach 5 (DevFast) Time |
Peak Memory Bytes (3 & 5) |
Remarks | Link |
|---|---|---|---|---|---|---|
| (Total Records = 1M, Uncompressed JSON File = 337,569,004 Bytes, GZip Compression) | ||||||
| Serialization | NONE | 31839 ms | 16599 ms | 647,816 K | DevFast is 47.86% faster |
Source Code |
| 256 | 41496 ms | 31614 ms | 45,388 K | DevFast is 23.81% faster |
||
| Deserialization2 | NONE | - | 14334 ms3 | 26,736 K3 | - | |
| 256 | - | 14634 ms3 | 26,744 K3 | - | ||
1Must be instrumented with sample data, especially when producer is faster than consumer.
2For Approach 3, no mechanism is known to fetch data in BlockingCollection directly! For DevFast only Compression & Looping considered (DB operations left for readers)
3Fast consumer effect (counting loop is faster than deserialization). This time can be viewed as pure PPC Pipeline Horsepower (Deserialization+Decompression time)
Here we wrote about what we have proposed until v1.1.2 and we have a lot more to propose and constraint by the time :( Nonetheless, we hope that this article has a lots of statistics, snapshots, and 1-liners for you.
Incessantly, we are adding more and more code in this lib, in order to bring you helpful one-liners. We would be happy to know your requirements and on the way, we'll prioritize those. Hope to see you back in a couple of months.
Useful links:
Let us know your thoughts.
<< Previous Article (Lets Shake Hands) |
Next Article (Meet Parallel Producers/Consumers) >> |