Mining the Social Web, 2nd Edition
Chapter 2: Mining Facebook: Analyzing Fan Pages, Examining Friendships, and More
This IPython Notebook provides an interactive way to follow along with and explore the numbered examples from Mining the Social Web (2nd Edition). The intent behind this notebook is to reinforce the concepts from the sample code in a fun, convenient, and effective way. This notebook assumes that you are reading along with the book and have the context of the discussion as you work through these exercises.
In the somewhat unlikely event that you've somehow stumbled across this notebook outside of its context on GitHub, you can find the full source code repository here.
Copyright and Licensing
You are free to use or adapt this notebook for any purpose you'd like. However, please respect the Simplified BSD License that governs its use.
Facebook API Access
Facebook implements OAuth 2.0 as its standard authentication mechanism, but provides a convenient way for you to get an access token for development purposes, and we'll opt to take advantage of that convenience in this notebook. For details on implementing an OAuth flow with Facebook (all from within IPython Notebook), see the _AppendixB notebook from the IPython Notebook Dashboard.
For this first example, login to your Facebook account and go to https://developers.facebook.com/tools/explorer/ to obtain and set permissions for an access token that you will need to define in the code cell defining the ACCESS_TOKEN variable below.
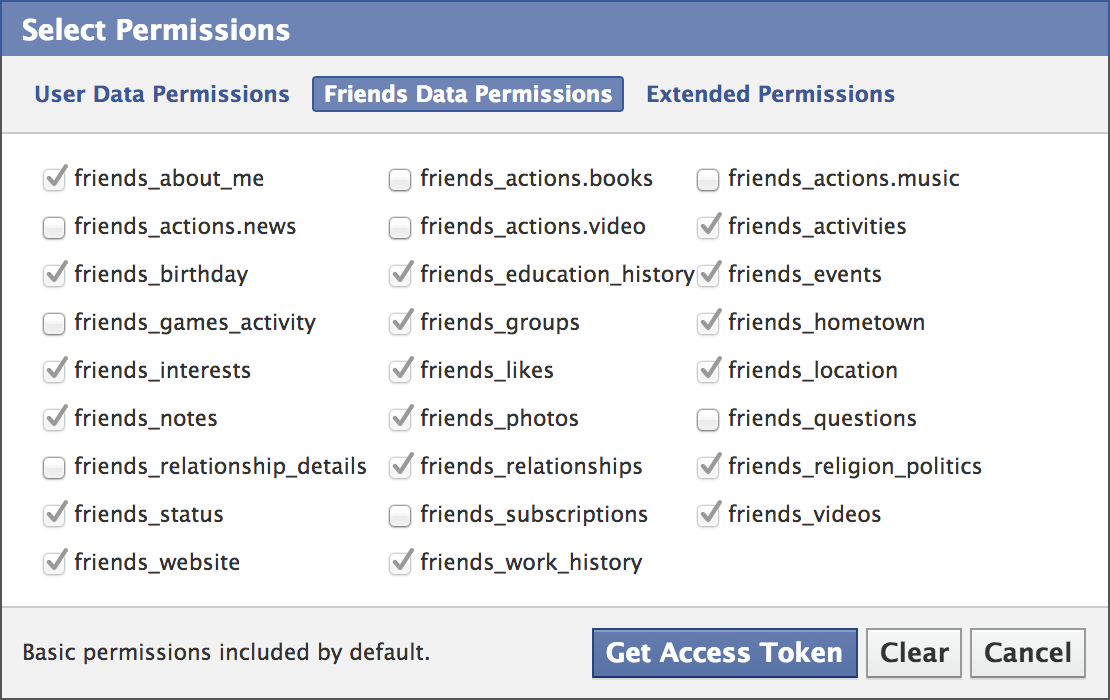
Be sure to explore the permissions that are available by clicking on the "Get Access Token" button that's on the page and exploring all of the tabs available. For example, you will need to set the "friends_likes" option under the "Friends Data Permissions" since this permission is used by the script below but is not a basic permission and is not enabled by default.
Note: If you attempt to run a query for all of your friends' likes and it appears to hang, it is probably because you have a lot of friends who have a lot of likes. If this happens, you may need to add limits and offsets to the fields in the query as described in Facebook's field expansion documentation. However, the facebook library that we'll use in the next example handles some of these issues, so it's recommended that you hold off and try it out first. This initial example is just to illustrate that Facebook's API is built on top of HTTP.
A couple of field limit/offset examples that illustrate the possibilities follow:
fields = 'id,name,friends.limit(10).fields(likes)' # Get all likes for 10 friends fields = 'id,name,friends.offset(10).limit(10).fields(likes)' # Get all likes for 10 more friends fields = 'id,name,friends.fields(likes.limit(10))' # Get 10 likes for all friends fields = 'id,name,friends.fields(likes.limit(10))' # Get 10 likes for all friends
Note: You may need to implement some filtering on the NetworkX graph before writing it out to a file for display in D3, and for more than dozens of nodes, it may not be reasonable to render a meaningful visualization without some JavaScript hacking on its parameters. View the JavaScript source in force.html for some of the details.