## The basic files and libraries needed for most presentations
# creates the libraries and common-functions sections
read_chunk("../common/utility_functions.R")
require(ggplot2) #for plots
require(lattice) # nicer scatter plots
require(plyr) # for processing data.frames
library(dplyr)
require(grid) # contains the arrow function
require(jpeg)
require(doMC) # for parallel code
require(png) # for reading png images
require(gridExtra)
require(reshape2) # for the melt function
#if (!require("biOps")) {
# # for basic image processing
# devtools::install_github("cran/biOps")
# library("biOps")
#}
## To install EBImage
if (!require("EBImage")) { # for more image processing
source("http://bioconductor.org/biocLite.R")
biocLite("EBImage")
}
used.libraries<-c("ggplot2","lattice","plyr","reshape2","grid","gridExtra","biOps","png","EBImage")
# start parallel environment
registerDoMC()
# functions for converting images back and forth
im.to.df<-function(in.img,out.col="val") {
out.im<-expand.grid(x=1:nrow(in.img),y=1:ncol(in.img))
out.im[,out.col]<-as.vector(in.img)
out.im
}
df.to.im<-function(in.df,val.col="val",inv=F) {
in.vals<-in.df[[val.col]]
if(class(in.vals[1])=="logical") in.vals<-as.integer(in.vals*255)
if(inv) in.vals<-255-in.vals
out.mat<-matrix(in.vals,nrow=length(unique(in.df$x)),byrow=F)
attr(out.mat,"type")<-"grey"
out.mat
}
ddply.cutcols<-function(...,cols=1) {
# run standard ddply command
cur.table<-ddply(...)
cutlabel.fixer<-function(oVal) {
sapply(oVal,function(x) {
cnv<-as.character(x)
mean(as.numeric(strsplit(substr(cnv,2,nchar(cnv)-1),",")[[1]]))
})
}
cutname.fixer<-function(c.str) {
s.str<-strsplit(c.str,"(",fixed=T)[[1]]
t.str<-strsplit(paste(s.str[c(2:length(s.str))],collapse="("),",")[[1]]
paste(t.str[c(1:length(t.str)-1)],collapse=",")
}
for(i in c(1:cols)) {
cur.table[,i]<-cutlabel.fixer(cur.table[,i])
names(cur.table)[i]<-cutname.fixer(names(cur.table)[i])
}
cur.table
}
# since biOps isn't available use a EBImage based version
imgSobel<-function(img) {
kern<-makeBrush(3)*(-1)
kern[2,2]<-8
filter2(img,kern)
}
show.pngs.as.grid<-function(file.list,title.fun,zoom=1) {
preparePng<-function(x) rasterGrob(readPNG(x,native=T,info=T),width=unit(zoom,"npc"),interp=F)
labelPng<-function(x,title="junk") (qplot(1:300, 1:300, geom="blank",xlab=NULL,ylab=NULL,asp=1)+
annotation_custom(preparePng(x))+
labs(title=title)+theme_bw(24)+
theme(axis.text.x = element_blank(),
axis.text.y = element_blank()))
imgList<-llply(file.list,function(x) labelPng(x,title.fun(x)) )
do.call(grid.arrange,imgList)
}
## Standard image processing tools which I use for visualizing the examples in the script
commean.fun<-function(in.df) {
ddply(in.df,.(val), function(c.cell) {
weight.sum<-sum(c.cell$weight)
data.frame(xv=mean(c.cell$x),
yv=mean(c.cell$y),
xm=with(c.cell,sum(x*weight)/weight.sum),
ym=with(c.cell,sum(y*weight)/weight.sum)
)
})
}
colMeans.df<-function(x,...) as.data.frame(t(colMeans(x,...)))
pca.fun<-function(in.df) {
ddply(in.df,.(val), function(c.cell) {
c.cell.cov<-cov(c.cell[,c("x","y")])
c.cell.eigen<-eigen(c.cell.cov)
c.cell.mean<-colMeans.df(c.cell[,c("x","y")])
out.df<-cbind(c.cell.mean,
data.frame(vx=c.cell.eigen$vectors[1,],
vy=c.cell.eigen$vectors[2,],
vw=sqrt(c.cell.eigen$values),
th.off=atan2(c.cell.eigen$vectors[2,],c.cell.eigen$vectors[1,]))
)
})
}
vec.to.ellipse<-function(pca.df) {
ddply(pca.df,.(val),function(cur.pca) {
# assume there are two vectors now
create.ellipse.points(x.off=cur.pca[1,"x"],y.off=cur.pca[1,"y"],
b=sqrt(5)*cur.pca[1,"vw"],a=sqrt(5)*cur.pca[2,"vw"],
th.off=pi/2-atan2(cur.pca[1,"vy"],cur.pca[1,"vx"]),
x.cent=cur.pca[1,"x"],y.cent=cur.pca[1,"y"])
})
}
# test function for ellipse generation
# ggplot(ldply(seq(-pi,pi,length.out=100),function(th) create.ellipse.points(a=1,b=2,th.off=th,th.val=th)),aes(x=x,y=y))+geom_path()+facet_wrap(~th.val)+coord_equal()
create.ellipse.points<-function(x.off=0,y.off=0,a=1,b=NULL,th.off=0,th.max=2*pi,pts=36,...) {
if (is.null(b)) b<-a
th<-seq(0,th.max,length.out=pts)
data.frame(x=a*cos(th.off)*cos(th)+b*sin(th.off)*sin(th)+x.off,
y=-1*a*sin(th.off)*cos(th)+b*cos(th.off)*sin(th)+y.off,
id=as.factor(paste(x.off,y.off,a,b,th.off,pts,sep=":")),...)
}
deform.ellipse.draw<-function(c.box) {
create.ellipse.points(x.off=c.box$x[1],
y.off=c.box$y[1],
a=c.box$a[1],
b=c.box$b[1],
th.off=c.box$th[1],
col=c.box$col[1])
}
bbox.fun<-function(in.df) {
ddply(in.df,.(val), function(c.cell) {
c.cell.mean<-colMeans.df(c.cell[,c("x","y")])
xmn<-emin(c.cell$x)
xmx<-emax(c.cell$x)
ymn<-emin(c.cell$y)
ymx<-emax(c.cell$y)
out.df<-cbind(c.cell.mean,
data.frame(xi=c(xmn,xmn,xmx,xmx,xmn),
yi=c(ymn,ymx,ymx,ymn,ymn),
xw=xmx-xmn,
yw=ymx-ymn
))
})
}
# since the edge of the pixel is 0.5 away from the middle of the pixel
emin<-function(...) min(...)-0.5
emax<-function(...) max(...)+0.5
extents.fun<-function(in.df) {
ddply(in.df,.(val), function(c.cell) {
c.cell.mean<-colMeans.df(c.cell[,c("x","y")])
out.df<-cbind(c.cell.mean,data.frame(xmin=c(c.cell.mean$x,emin(c.cell$x)),
xmax=c(c.cell.mean$x,emax(c.cell$x)),
ymin=c(emin(c.cell$y),c.cell.mean$y),
ymax=c(emax(c.cell$y),c.cell.mean$y)))
})
}
common.image.path<-"../common"
qbi.file<-function(file.name) file.path(common.image.path,"figures",file.name)
qbi.data<-function(file.name) file.path(common.image.path,"data",file.name)
th_fillmap.fn<-function(max.val) scale_fill_gradientn(colours=rainbow(10),limits=c(0,max.val))
Quantitative Big Imaging
========================================================
author: Kevin Mader
date: 17 March 2016
width: 1440
height: 900
css: ../common/template.css
transition: rotate
ETHZ: 227-0966-00L
## Advanced Segmentation
Course Outline
========================================================
source('../common/schedule.R')
- 25th February - Introduction and Workflows
- 3rd March - Image Enhancement (A. Kaestner)
- 10th March - Basic Segmentation, Discrete Binary Structures
- 17th March - Advanced Segmentation
- 24th March - Analyzing Single Objects
- 7th April - Analyzing Complex Objects
- 14th April - Spatial Distribution
- 21st April - Statistics and Reproducibility
- 28th April - Dynamic Experiments
- 12th May - Scaling Up / Big Data
- 19th May - Guest Lecture - High Content Screening
- 26th May - Guest Lecture - Machine Learning / Deep Learning and More Advanced Approaches
- 2nd June - Project Presentations
Literature / Useful References
========================================================
- Jean Claude, Morphometry with R
- [Online](http://link.springer.com/book/10.1007%2F978-0-387-77789-4) through ETHZ
- [Buy it](http://www.amazon.com/Morphometrics-R-Use-Julien-Claude/dp/038777789X)
- John C. Russ, “The Image Processing Handbook”,(Boca Raton, CRC Press)
- Available [online](http://dx.doi.org/10.1201/9780203881095) within domain ethz.ch (or proxy.ethz.ch / public VPN)
### Advanced Segmentation
- [Markov Random Fields for Image Processing Lecture](https://www.youtube.com/watch?v=vRN_j2j-CC4)
- [Markov Random Fields Chapter](http://www.cise.ufl.edu/~anand/pdf/bookchap.pdf)
- [Fuzzy set theory](http://www.academia.edu/4978200/Applications_of_Fuzzy_Set_Theory_and_Fuzzy_Logic_in_Image_Processing)
- [Superpixels](http://ivrg.epfl.ch/research/superpixels)
***
### Contouring
- [Active Contours / Snakes](http://link.springer.com/article/10.1007%2FBF00133570#page-1)
Lesson Outline
========================================================
- Motivation
- Many Samples
- Difficult Samples
- Training / Learning
- Thresholding
- Automated Methods
- Hysteresis Method
***
- Feature Vectors
- K-Means Clustering
- Superpixels
- Probabalistic Models
- Working with Segmented Images
- Contouring
- Beyond
- Fuzzy Models
- Component Labeling
Previously on QBI
========================================================
- Image acquisition and representations
- Enhancement and noise reduction
- Understanding models and interpreting histograms
- Ground Truth and ROC Curves
***
- Choosing a threshold
- Examining more complicated, multivariate data sets
- Improving segementation with morphological operations
- Filling holes
- Connecting objects
- Removing Noise
- Partial Volume Effect
Where segmentation fails: Inconsistent Illumination
========================================================
With inconsistent or every changing illumination it may not be possible to apply the same threshold to every image.
Where segmentation fails: Canaliculi
========================================================

### Here is a bone slice
1. Find the larger cellular structures (osteocyte lacunae)
1. Find the small channels which connect them together
***
### The first task
is easy using a threshold and size criteria (we know how big the cells should be)
### The second
is much more difficult because the small channels having radii on the same order of the pixel size are obscured by partial volume effects and noise.
Where segmentation fails: Brain Cortex
========================================================
- The cortex is barely visible to the human eye
- Tiny structures hint at where cortex is located
Automated Threshold Selection
========================================================

***
Given that applying a threshold is such a common and signficant step, there have been many tools developed to automatically (unsupervised) perform it. A particularly important step in setups where images are rarely consistent such as outdoor imaging which has varying lighting (sun, clouds). The methods are based on several basic principles.
Automated Methods
===
### Histogram-based methods
Just like we visually inspect a histogram an algorithm can examine the histogram and find local minimums between two peaks, maximum / minimum entropy and other factors
- Otsu, Isodata, Intermodes, etc
### Image based Methods
These look at the statistics of the thresheld image themselves (like entropy) to estimate the threshold
### Results-based Methods
These search for a threshold which delivers the desired results in the final objects. For example if you know you have an image of cells and each cell is between 200-10000 pixels the algorithm runs thresholds until the objects are of the desired size
- More specific requirements need to be implemented manually
Histogram Methods
===
Taking a typical image of a bone slice, we can examine the variations in calcification density in the image
***
### Intermodes
- Take the point between the two modes (peaks) in the histogram
### Otsu
Search and minimize intra-class (within) variance
$$\sigma^2_w(t)=\omega_{bg}(t)\sigma^2_{bg}(t)+\omega_{fg}(t)\sigma^2_{fg}(t)$$
### Isodata
- $\textrm{thresh}= \max(img)+\min(img)/2$
- _while_ the thresh is changing
- $bg = img<\textrm{thresh}, obj = img>\textrm{thresh}$
- $\textrm{thresh} = (\textrm{avg}(bg) + \textrm{avg}(obj))/2$
Fiji -> Adjust -> Auto Threshold
========================================================
There are many methods and they can be complicated to implement yourself. FIJI offers many of them as built in functions so you can automatically try all of them on your image

Pitfalls
===
While an incredibly useful tool, there are many potential pitfalls to these automated techniques.
### Histogram-based
These methods are very sensitive to the distribution of pixels in your image and may work really well on images with equal amounts of each phase but work horribly on images which have very high amounts of one phase compared to the others
### Image-based
These methods are sensitive to noise and a large noise content in the image can change statistics like entropy significantly.
### Results-based
These methods are inherently biased by the expectations you have. If you want to find objects between 200 and 1000 pixels you will, they just might not be anything meaningful.
Realistic Approaches for Dealing with these Shortcomings
===
Imaging science rarely represents the ideal world and will never be 100% perfect. At some point we need to write our master's thesis, defend, or publish a paper. These are approaches for more qualitative assessment we will later cover how to do this a bit more robustly with quantitative approaches
### Model-based
One approach is to try and simulate everything (including noise) as well as possible and to apply these techniques to many realizations of the same image and qualitatively keep track of how many of the results accurately identify your phase or not. Hint: >95% seems to convince most biologists
### Sample-based
Apply the methods to each sample and keep track of which threshold was used for each one. Go back and apply each threshold to each sample in the image and keep track of how many of them are correct enough to be used for further study.
### Worst-case Scenario
Come up with the worst-case scenario (noise, misalignment, etc) and assess how inacceptable the results are. Then try to estimate the quartiles range (75% - 25% of images).
Hysteresis Thresholding
========================================================
For some images a single threshold does not work
- large structures are very clearly defined
- smaller structures are difficult to differentiated (see [partial volume effect](http://bit.ly/1mW7kdP))
[ImageJ Source](http://imagejdocu.tudor.lu/doku.php?id=plugin:segmentation:hysteresis_thresholding:start)
Hysteresis Thresholding: Reducing Pixels
========================================================
Now we apply two important steps. The first is to remove the objects which are not cells (too small) using an opening operation.
# if its air make sure its still air otherwise demote it to between,
# if its not air leave it alone
nbone.df$phase<-ifelse(nbone.df$phase=="Air",
ifelse(nbone.df$stillair>0,"Air","Between"),
nbone.df$phase)
***
The second step to keep the _between_ pixels which are connected (by looking again at a neighborhood $\mathcal{N}$) to the _air_ voxels and ignore the other ones. This goes back to our original supposition that the smaller structures are connected to the larger structures
# incredibly low performance implementation (please do not copy)
bone.idf<-nbone.df
bet.pts<-nbone.df
# run while there is still new air being created
while(nrow(subset(bet.pts,phase=="Air"))>0) {
air.pts<-subset(bone.idf,phase=="Air")[,c("x","y")]
bone.pts<-subset(bone.idf,phase=="Bone")[,c("x","y")]
bet.pts<-ddply(subset(bone.idf,phase=="Between"),.(x,y),function(in.pixel.lst) {
in.pixel<-in.pixel.lst[1,]
data.frame(phase=ifelse(min(with(air.pts,(in.pixel$x-x)^2+(in.pixel$y-y)^2))<=1,
"Air",
"Between"))
})
bone.idf<-rbind(bet.pts,
cbind(air.pts,phase="Air"),
cbind(bone.pts,phase="Bone"))
print(nrow(subset(bet.pts,phase=="Air")))
}
ggplot(bone.idf,aes(x=x,y=y))+
geom_raster(aes(fill=phase))+
labs(fill="Phase",y="y",x="x")+
coord_equal()+
theme_bw(20)
More Complicated Images
===
As we briefly covered last time, many measurement techniques produce quite rich data.
- Digital cameras produce 3 channels of color for each pixel (rather than just one intensity)
- MRI produces dozens of pieces of information for every voxel which are used when examining different _contrasts_ in the system.
- Raman-shift imaging produces an entire spectrum for each pixel
- Coherent diffraction techniques produce 2- (sometimes 3) diffraction patterns for each point.
$$ I(x,y) = \hat{f}(x,y) $$
***
Feature Vectors
===
__A pairing between spatial information (position) and some other kind of information (value).__
$$ \vec{x} \rightarrow \vec{f} $$
We are used to seeing images in a grid format where the position indicates the row and column in the grid and the intensity (absorption, reflection, tip deflection, etc) is shown as a different color
This representation can be called the __feature vector__ and in this case it only has Intensity
Why Feature Vectors
===
If we use feature vectors to describe our image, we are no longer to worrying about how the images will be displayed, and can focus on the segmentation/thresholding problem from a classification rather than a image-processing stand point.
### Example
So we have an image of a cell and we want to identify the membrane (the ring) from the nucleus (the point in the middle).
***
A simple threshold doesn't work because we identify the point in the middle as well. We could try to use morphological tricks to get rid of the point in the middle, or we could better tune our segmentation to the ring structure.
Applying two criteria
===
Now instead of trying to find the intensity for the ring, we can combine density and distance to identify it
$$ iff (5<\textrm{Distance}<10 \\ \& 0.3<\textrm{Intensity}>1.0) $$
Common Features
===
The distance while illustrative is not a commonly used features, more common various filters applied to the image
- Gaussian Filter (information on the values of the surrounding pixels)
- Sobel / Canny Edge Detection (information on edges in the vicinity)
- Entroy (information on variability in vicinity)
Analyzing the feature vector
===
The distributions of the features appear very different and can thus likely be used for identifying different parts of the images.
## Error in eval(expr, envir, enclos): object 'merged.ring.image' not found
K-Means Clustering / Classification (Unsupervised)
===
- Automatic clustering of multidimensional data into groups based on a distance metric
- Fast and scalable to petabytes of data (Google, Facebook, Twitter, etc. use it regularly to classify customers, advertisements, queries)
- __Input__ = feature vectors, distance metric, number of groups
- __Output__ = a classification for each feature vector to a group
K-Means Example
===
### Input
- Feature vectors ($\vec{v}$)
K-Means Algorithm
===
We give as an initial parameter the number of groups we want to find and possible a criteria for removing groups that are too similar
1. Randomly create center points (groups) in vector space
1. Assigns group to data point by the “closest” center
1. Recalculate centers from mean point in each group
1. Go back to step 2 until the groups stop changing
***
What vector space to we have?
- Sometimes represent physical locations (classify swiss people into cities)
- Can include intensity or color (K-means can be used as a thresholding technique when you give it image intensity as the vector and tell it to find two or more groups)
- Can also include orientation, shape, or in extreme cases full spectra (chemically sensitive imaging)
#### Note: If you look for N groups you will almost always find N groups with K-Means, whether or not they make any sense
K-Means Example
===
Continuing with our previous image and applying K-means to the Intensity, Sobel and Gaussian channels looking for 2 groups we find
## Error in eval(expr, envir, enclos): object 'sring.image' not found
Rescaling components
===
Since the distance is currently calculated by $||\vec{v}_i-\vec{v}_j||$ and the values for the position is much larger than the values for the _Intensity_, _Sobel_ or _Gaussian_ they need to be rescaled so they all fit on the same axis
$$\vec{v} = \left\{\frac{x}{10}, \frac{y}{10}, \textrm{Intensity},\textrm{Sobel},\textrm{Gaussian}\right\}$$
pos.scale<-5
shale.kmeans.data<-mutate(
shale.image[,c("x","y","Intensity")],
x=x/pos.scale,y=y/pos.scale)
# evenly spaced grid
grid.size<-40
grid.center<-round(grid.size/2)
shale.superpixels.centers<-subset(shale.kmeans.data,
x%%grid.size==grid.center & x%%grid.size==grid.center)
# not the real super pixels algorithm but close enough, see paper and websites
# http://www.kev-smith.com/papers/SLIC_Superpixels.pdf
# http://ivrg.epfl.ch/research/superpixels
shale.kmeans<-kmeans(shale.kmeans.data,
centers=shale.superpixels.centers,
iter.max=50
)
shale.image$km.cluster<-shale.kmeans$cluster
Probabilistic Models of Segmentation
===
A more general approach is to use a probabilistic model to segmentation. We start with our image $I(\vec{x}) \forall \vec{x}\in \mathbb{R}^N$ and we classify it into two phases $\alpha$ and $\beta$
$$P(\{\vec{x} , I(\vec{x})\} | \alpha) \propto P(\alpha) + P(I(\vec{x}) | \alpha)+ P(\sum_{x^{\prime} \in \mathcal{N}} I(\vec{x^{\prime}}) | \alpha)$$
- $P(\{\vec{x} , f(\vec{x})\} | \alpha)$ the probability a given pixel is in phase $\alpha$ given we know it's position and value (what we are trying to estimate)
- $P(\alpha)$ probability of any pixel in an image being part of the phase (expected volume fraction of that phase)
- $P(I(\vec{x}) | \alpha)$ probability adjustment based on knowing the value of $I$ at the given point (standard threshold)
- $P(f(\vec{x^{\prime}}) | \alpha)$ are the collective probability adjustments based on knowing the value of a pixels neighbors (very simple version of [Markov Random Field](http://en.wikipedia.org/wiki/Markov_random_field) approaches)
Contouring
===
Expanding on the hole filling issues examined before, a general problem in imaging is identifying regions of interest with in an image.
- For samples like brains it is done to identify different regions of the brain which are responsible for different functions.
- In material science it might be done to identify a portion of the sample being heated or understress.
- There are a number of approaches depending on the clarity of the data and the
Convex Hull Approach
===
takes all of the points in a given slice or volume and finds the smallest convex 2D area or 3D volume (respectively) which encloses all of those points.
Convex Hull Example
===
The convex hull very closely matches the area we would define as 'bone' without requiring any parameter adjustment, resolution specific adjustments, or extensive image-processing, for such a sample a convex hull is usually sufficient.
***
Here is an example of the convex hull applied to a region of a cortical bone sample. The green shows the bone and the red shows the convex hull. Compared to a visual inspection, the convex hull overestimates the bone area as we probably would not associate the region where the bone curves to the right with 'bone area'
## the rubber band function to fit a boundary around the curve
rubber.band.data<-function(raw.df,binning.pts=10,eval.fun=max) {
in.df<-raw.df
# calculate center of mass
com.val<-colMeans(in.df)
# add polar coordinates
in.df$r<-with(in.df,sqrt((x-com.val["x"])^2+(y-com.val["y"])^2))
in.df$theta<-with(in.df,atan2(y-com.val["y"],x-com.val["x"]))
# create a maximum path
outer.path<-ddply.cutcols(in.df,.(cut_interval(theta,binning.pts)),function(c.section) data.frame(r=eval.fun(c.section$r)))
outer.path$x<-with(outer.path,r*cos(theta)+com.val["x"])
outer.path$y<-with(outer.path,r*sin(theta)+com.val["y"])
outer.path
}
Useful for a variety of samples (needn't be radially symmetric) and offers more flexibility in step size, smoothing function etc than convex hull.
1. Calculates the center of mass.
1. Transforms sample into Polar Coordinates
1. Calculates a piecewise linear fit $r=f(\theta)$
ggplot(subset(cortbone.df,val<1),aes(x=x,y=518-y))+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),9),aes(fill="rubber band 9pts"),alpha=0.5)+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),36),aes(fill="rubber band 36pts"),alpha=0.5)+
geom_raster(aes(fill="original"),alpha=0.8)+
labs(fill="Image",y="y",x="x")+
coord_equal()+
theme_bw(20)
***
ggplot(subset(cortbone.df,val<1),aes(x=x,y=518-y))+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),90),aes(fill="rubber band 90pts"),alpha=0.5)+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),180),aes(fill="rubber band 180pts"),alpha=0.5)+
geom_raster(aes(fill="original"),alpha=0.8)+
labs(fill="Image",y="y",x="x")+
coord_equal()+
theme_bw(20)
ggplot(subset(cortbone.df,val<1),aes(x=x,y=518-y))+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),180),aes(fill="rubber band 180pts"),alpha=0.5)+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),720),aes(fill="rubber band 720pts"),alpha=0.5)+
geom_raster(aes(fill="original"),alpha=0.8)+
labs(fill="Image",y="y",x="x")+
coord_equal()+xlim(50,150)+ylim(-100,50)+
theme_bw(20)
Rubber Band: More flexible constraints
===
If we use quartiles or the average instead of the maximum value we can make the method less sensitive to outlier pixels
ggplot(subset(cortbone.df,val<1),aes(x=x,y=518-y))+
geom_raster(aes(fill="original"),alpha=0.8)+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),90,eval.fun=mean),
aes(fill="rubber band mean value"),alpha=0.5)+
geom_polygon(data=rubber.band.data(subset(cortbone.df,val<1),90,
eval.fun=function(x) quantile(x,0.99)),
aes(fill="rubber band upper 99%"),alpha=0.5)+
labs(fill="Image",y="y",x="x")+
coord_equal()+
theme_bw(20)
Contouring: Manual - Guided Methods
===
Many forms of guided methods exist, the most popular is known simply as the _Magnetic Lasso_ in Adobe Photoshop ([video](http://people.ee.ethz.ch/~maderk/videos/MagneticLasso.swf)).
The basic principal behind many of these methods is to optimize a set of user given points based on local edge-like information in the image. In the brain cortex example, this is the small gradients in the gray values which our eyes naturally seperate out as an edge but which have many gaps and discontinuities.
[Active Contours / Snakes](http://link.springer.com/article/10.1007%2FBF00133570#page-1)
Beyond
===
- A multitude of other techniques exist for classifying groups and courses in Data Science and Artificial Intelligence go into much greater details.
- These techniques are generally underused because they are complicated to explain and robustly test and can arouse suspicion from reviewers.
- Because of their added complexity it is easier to manipulate these methods to get desired results from almost any dataset
- But if the approach is based on a physical model of the images and the underyling system it is acceptable
- Additionally they usually require some degree of implementation (coding).
Fuzzy Classification
===
Fuzzy classification based on [Fuzzy logic](http://en.wikipedia.org/wiki/Fuzzy_logic) and [Fuzzy set theory](http://www.academia.edu/4978200/Applications_of_Fuzzy_Set_Theory_and_Fuzzy_Logic_in_Image_Processing) and is a general catagory for multi-value logic instead of simply __true__ and __false__ and can be used to build __IF__ and __THEN__ statements from our probabilistic models.
### Instead of
$$P(\{\vec{x} , I(\vec{x})\} | \alpha) \propto P(\alpha) + P(I(\vec{x}) | \alpha)+$$
$$P(\sum_{x^{\prime} \in \mathcal{N}} I(\vec{x^{\prime}}) | \alpha)$$
***
### Clear simple rules
which encompass aspects of filtering, thresholding, and morphological operations
- __IF__ the intensity if dark ($<100$)
- __AND__ a majority of the neighborhood ($\mathcal{N}$) values are dark ($<100$)
- __THEN__ it is a cell


 Where segmentation fails: Canaliculi
========================================================

### Here is a bone slice
1. Find the larger cellular structures (osteocyte lacunae)
1. Find the small channels which connect them together
***
### The first task
is easy using a threshold and size criteria (we know how big the cells should be)
### The second
is much more difficult because the small channels having radii on the same order of the pixel size are obscured by partial volume effects and noise.
Where segmentation fails: Brain Cortex
========================================================
- The cortex is barely visible to the human eye
- Tiny structures hint at where cortex is located
Where segmentation fails: Canaliculi
========================================================

### Here is a bone slice
1. Find the larger cellular structures (osteocyte lacunae)
1. Find the small channels which connect them together
***
### The first task
is easy using a threshold and size criteria (we know how big the cells should be)
### The second
is much more difficult because the small channels having radii on the same order of the pixel size are obscured by partial volume effects and noise.
Where segmentation fails: Brain Cortex
========================================================
- The cortex is barely visible to the human eye
- Tiny structures hint at where cortex is located
 ***
- A simple threshold is insufficient to finding the cortical structures
- Other filtering techniques are unlikely to magicially fix this problem
***
- A simple threshold is insufficient to finding the cortical structures
- Other filtering techniques are unlikely to magicially fix this problem
 Automated Threshold Selection
========================================================

***
Given that applying a threshold is such a common and signficant step, there have been many tools developed to automatically (unsupervised) perform it. A particularly important step in setups where images are rarely consistent such as outdoor imaging which has varying lighting (sun, clouds). The methods are based on several basic principles.
Automated Methods
===
### Histogram-based methods
Just like we visually inspect a histogram an algorithm can examine the histogram and find local minimums between two peaks, maximum / minimum entropy and other factors
- Otsu, Isodata, Intermodes, etc
### Image based Methods
These look at the statistics of the thresheld image themselves (like entropy) to estimate the threshold
### Results-based Methods
These search for a threshold which delivers the desired results in the final objects. For example if you know you have an image of cells and each cell is between 200-10000 pixels the algorithm runs thresholds until the objects are of the desired size
- More specific requirements need to be implemented manually
Histogram Methods
===
Taking a typical image of a bone slice, we can examine the variations in calcification density in the image
Automated Threshold Selection
========================================================

***
Given that applying a threshold is such a common and signficant step, there have been many tools developed to automatically (unsupervised) perform it. A particularly important step in setups where images are rarely consistent such as outdoor imaging which has varying lighting (sun, clouds). The methods are based on several basic principles.
Automated Methods
===
### Histogram-based methods
Just like we visually inspect a histogram an algorithm can examine the histogram and find local minimums between two peaks, maximum / minimum entropy and other factors
- Otsu, Isodata, Intermodes, etc
### Image based Methods
These look at the statistics of the thresheld image themselves (like entropy) to estimate the threshold
### Results-based Methods
These search for a threshold which delivers the desired results in the final objects. For example if you know you have an image of cells and each cell is between 200-10000 pixels the algorithm runs thresholds until the objects are of the desired size
- More specific requirements need to be implemented manually
Histogram Methods
===
Taking a typical image of a bone slice, we can examine the variations in calcification density in the image
 ***
We can see in the histogram that there are two peaks, one at 0 (no absorption / air) and one at 0.5 (stronger absorption / bone)
***
We can see in the histogram that there are two peaks, one at 0 (no absorption / air) and one at 0.5 (stronger absorption / bone)
 Histogram Methods
===
Histogram Methods
===
 ***
### Intermodes
- Take the point between the two modes (peaks) in the histogram
### Otsu
Search and minimize intra-class (within) variance
$$\sigma^2_w(t)=\omega_{bg}(t)\sigma^2_{bg}(t)+\omega_{fg}(t)\sigma^2_{fg}(t)$$
### Isodata
- $\textrm{thresh}= \max(img)+\min(img)/2$
- _while_ the thresh is changing
- $bg = img<\textrm{thresh}, obj = img>\textrm{thresh}$
- $\textrm{thresh} = (\textrm{avg}(bg) + \textrm{avg}(obj))/2$
Fiji -> Adjust -> Auto Threshold
========================================================
There are many methods and they can be complicated to implement yourself. FIJI offers many of them as built in functions so you can automatically try all of them on your image

Pitfalls
===
While an incredibly useful tool, there are many potential pitfalls to these automated techniques.
### Histogram-based
These methods are very sensitive to the distribution of pixels in your image and may work really well on images with equal amounts of each phase but work horribly on images which have very high amounts of one phase compared to the others
### Image-based
These methods are sensitive to noise and a large noise content in the image can change statistics like entropy significantly.
### Results-based
These methods are inherently biased by the expectations you have. If you want to find objects between 200 and 1000 pixels you will, they just might not be anything meaningful.
Realistic Approaches for Dealing with these Shortcomings
===
Imaging science rarely represents the ideal world and will never be 100% perfect. At some point we need to write our master's thesis, defend, or publish a paper. These are approaches for more qualitative assessment we will later cover how to do this a bit more robustly with quantitative approaches
### Model-based
One approach is to try and simulate everything (including noise) as well as possible and to apply these techniques to many realizations of the same image and qualitatively keep track of how many of the results accurately identify your phase or not. Hint: >95% seems to convince most biologists
### Sample-based
Apply the methods to each sample and keep track of which threshold was used for each one. Go back and apply each threshold to each sample in the image and keep track of how many of them are correct enough to be used for further study.
### Worst-case Scenario
Come up with the worst-case scenario (noise, misalignment, etc) and assess how inacceptable the results are. Then try to estimate the quartiles range (75% - 25% of images).
Hysteresis Thresholding
========================================================
For some images a single threshold does not work
- large structures are very clearly defined
- smaller structures are difficult to differentiated (see [partial volume effect](http://bit.ly/1mW7kdP))
[ImageJ Source](http://imagejdocu.tudor.lu/doku.php?id=plugin:segmentation:hysteresis_thresholding:start)
***
### Intermodes
- Take the point between the two modes (peaks) in the histogram
### Otsu
Search and minimize intra-class (within) variance
$$\sigma^2_w(t)=\omega_{bg}(t)\sigma^2_{bg}(t)+\omega_{fg}(t)\sigma^2_{fg}(t)$$
### Isodata
- $\textrm{thresh}= \max(img)+\min(img)/2$
- _while_ the thresh is changing
- $bg = img<\textrm{thresh}, obj = img>\textrm{thresh}$
- $\textrm{thresh} = (\textrm{avg}(bg) + \textrm{avg}(obj))/2$
Fiji -> Adjust -> Auto Threshold
========================================================
There are many methods and they can be complicated to implement yourself. FIJI offers many of them as built in functions so you can automatically try all of them on your image

Pitfalls
===
While an incredibly useful tool, there are many potential pitfalls to these automated techniques.
### Histogram-based
These methods are very sensitive to the distribution of pixels in your image and may work really well on images with equal amounts of each phase but work horribly on images which have very high amounts of one phase compared to the others
### Image-based
These methods are sensitive to noise and a large noise content in the image can change statistics like entropy significantly.
### Results-based
These methods are inherently biased by the expectations you have. If you want to find objects between 200 and 1000 pixels you will, they just might not be anything meaningful.
Realistic Approaches for Dealing with these Shortcomings
===
Imaging science rarely represents the ideal world and will never be 100% perfect. At some point we need to write our master's thesis, defend, or publish a paper. These are approaches for more qualitative assessment we will later cover how to do this a bit more robustly with quantitative approaches
### Model-based
One approach is to try and simulate everything (including noise) as well as possible and to apply these techniques to many realizations of the same image and qualitatively keep track of how many of the results accurately identify your phase or not. Hint: >95% seems to convince most biologists
### Sample-based
Apply the methods to each sample and keep track of which threshold was used for each one. Go back and apply each threshold to each sample in the image and keep track of how many of them are correct enough to be used for further study.
### Worst-case Scenario
Come up with the worst-case scenario (noise, misalignment, etc) and assess how inacceptable the results are. Then try to estimate the quartiles range (75% - 25% of images).
Hysteresis Thresholding
========================================================
For some images a single threshold does not work
- large structures are very clearly defined
- smaller structures are difficult to differentiated (see [partial volume effect](http://bit.ly/1mW7kdP))
[ImageJ Source](http://imagejdocu.tudor.lu/doku.php?id=plugin:segmentation:hysteresis_thresholding:start)
 ***
***

 Hysteresis Thresholding
========================================================
Comparing the original image with the three phases
Hysteresis Thresholding
========================================================
Comparing the original image with the three phases
 ***
***
 Hysteresis Thresholding: Reducing Pixels
========================================================
Now we apply two important steps. The first is to remove the objects which are not cells (too small) using an opening operation.
Hysteresis Thresholding: Reducing Pixels
========================================================
Now we apply two important steps. The first is to remove the objects which are not cells (too small) using an opening operation.

 More Complicated Images
===
As we briefly covered last time, many measurement techniques produce quite rich data.
- Digital cameras produce 3 channels of color for each pixel (rather than just one intensity)
- MRI produces dozens of pieces of information for every voxel which are used when examining different _contrasts_ in the system.
- Raman-shift imaging produces an entire spectrum for each pixel
- Coherent diffraction techniques produce 2- (sometimes 3) diffraction patterns for each point.
$$ I(x,y) = \hat{f}(x,y) $$
***
More Complicated Images
===
As we briefly covered last time, many measurement techniques produce quite rich data.
- Digital cameras produce 3 channels of color for each pixel (rather than just one intensity)
- MRI produces dozens of pieces of information for every voxel which are used when examining different _contrasts_ in the system.
- Raman-shift imaging produces an entire spectrum for each pixel
- Coherent diffraction techniques produce 2- (sometimes 3) diffraction patterns for each point.
$$ I(x,y) = \hat{f}(x,y) $$
***
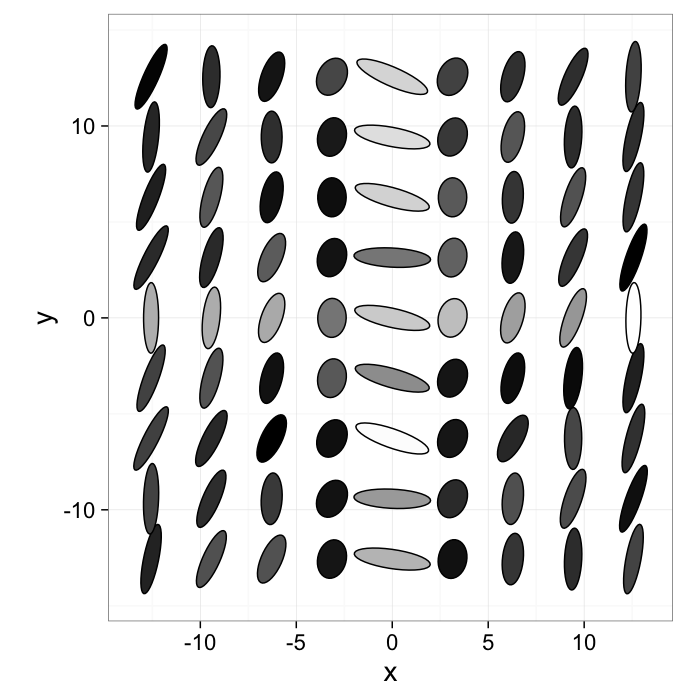 Feature Vectors
===
__A pairing between spatial information (position) and some other kind of information (value).__
$$ \vec{x} \rightarrow \vec{f} $$
We are used to seeing images in a grid format where the position indicates the row and column in the grid and the intensity (absorption, reflection, tip deflection, etc) is shown as a different color
Feature Vectors
===
__A pairing between spatial information (position) and some other kind of information (value).__
$$ \vec{x} \rightarrow \vec{f} $$
We are used to seeing images in a grid format where the position indicates the row and column in the grid and the intensity (absorption, reflection, tip deflection, etc) is shown as a different color
 ***
The alternative form for this image is as a list of positions and a corresponding value
$$ \hat{I} = (\vec{x},\vec{f}) $$
***
The alternative form for this image is as a list of positions and a corresponding value
$$ \hat{I} = (\vec{x},\vec{f}) $$
 ***
A simple threshold doesn't work because we identify the point in the middle as well. We could try to use morphological tricks to get rid of the point in the middle, or we could better tune our segmentation to the ring structure.
***
A simple threshold doesn't work because we identify the point in the middle as well. We could try to use morphological tricks to get rid of the point in the middle, or we could better tune our segmentation to the ring structure.
 Adding a new feature
===
In this case we add a very simple feature to the image, the distance from the center of the image (distance).
Adding a new feature
===
In this case we add a very simple feature to the image, the distance from the center of the image (distance).

 Applying two criteria
===
Now instead of trying to find the intensity for the ring, we can combine density and distance to identify it
$$ iff (5<\textrm{Distance}<10 \\ \& 0.3<\textrm{Intensity}>1.0) $$
Applying two criteria
===
Now instead of trying to find the intensity for the ring, we can combine density and distance to identify it
$$ iff (5<\textrm{Distance}<10 \\ \& 0.3<\textrm{Intensity}>1.0) $$
 ***
***
 Back to Ground Truth / ROC Curves
===
Back to Ground Truth / ROC Curves
===
 Examining the ROC Curve
===
Examining the ROC Curve
===
 ***
***
 ROC: True Positive Rate vs False Positive
===
ROC: True Positive Rate vs False Positive
===
 Common Features
===
The distance while illustrative is not a commonly used features, more common various filters applied to the image
- Gaussian Filter (information on the values of the surrounding pixels)
- Sobel / Canny Edge Detection (information on edges in the vicinity)
- Entroy (information on variability in vicinity)
Common Features
===
The distance while illustrative is not a commonly used features, more common various filters applied to the image
- Gaussian Filter (information on the values of the surrounding pixels)
- Sobel / Canny Edge Detection (information on edges in the vicinity)
- Entroy (information on variability in vicinity)
 Analyzing the feature vector
===
The distributions of the features appear very different and can thus likely be used for identifying different parts of the images.
Analyzing the feature vector
===
The distributions of the features appear very different and can thus likely be used for identifying different parts of the images.
 ***
Combine this with our _a priori_ information (called supervised analysis)
***
Combine this with our _a priori_ information (called supervised analysis)



 ***
***
 ***
***
 ***
***
 Why use superpixels
===
Drastically reduced data size, serves as an initial segmentation showing spatially meaningful groups
Why use superpixels
===
Drastically reduced data size, serves as an initial segmentation showing spatially meaningful groups
 ***
***
 Segment the superpixels and apply them to the whole image (only a fraction of the data and much smaller datasets)
Segment the superpixels and apply them to the whole image (only a fraction of the data and much smaller datasets)
 Superpixels vs Standard Segmentation
===
### Superpixels (0.06% of the original)
Superpixels vs Standard Segmentation
===
### Superpixels (0.06% of the original)
 ***
### Original
***
### Original
 Probabilistic Models of Segmentation
===
A more general approach is to use a probabilistic model to segmentation. We start with our image $I(\vec{x}) \forall \vec{x}\in \mathbb{R}^N$ and we classify it into two phases $\alpha$ and $\beta$
$$P(\{\vec{x} , I(\vec{x})\} | \alpha) \propto P(\alpha) + P(I(\vec{x}) | \alpha)+ P(\sum_{x^{\prime} \in \mathcal{N}} I(\vec{x^{\prime}}) | \alpha)$$
- $P(\{\vec{x} , f(\vec{x})\} | \alpha)$ the probability a given pixel is in phase $\alpha$ given we know it's position and value (what we are trying to estimate)
- $P(\alpha)$ probability of any pixel in an image being part of the phase (expected volume fraction of that phase)
- $P(I(\vec{x}) | \alpha)$ probability adjustment based on knowing the value of $I$ at the given point (standard threshold)
- $P(f(\vec{x^{\prime}}) | \alpha)$ are the collective probability adjustments based on knowing the value of a pixels neighbors (very simple version of [Markov Random Field](http://en.wikipedia.org/wiki/Markov_random_field) approaches)
Contouring
===
Expanding on the hole filling issues examined before, a general problem in imaging is identifying regions of interest with in an image.
- For samples like brains it is done to identify different regions of the brain which are responsible for different functions.
- In material science it might be done to identify a portion of the sample being heated or understress.
- There are a number of approaches depending on the clarity of the data and the
Convex Hull Approach
===
takes all of the points in a given slice or volume and finds the smallest convex 2D area or 3D volume (respectively) which encloses all of those points.
Probabilistic Models of Segmentation
===
A more general approach is to use a probabilistic model to segmentation. We start with our image $I(\vec{x}) \forall \vec{x}\in \mathbb{R}^N$ and we classify it into two phases $\alpha$ and $\beta$
$$P(\{\vec{x} , I(\vec{x})\} | \alpha) \propto P(\alpha) + P(I(\vec{x}) | \alpha)+ P(\sum_{x^{\prime} \in \mathcal{N}} I(\vec{x^{\prime}}) | \alpha)$$
- $P(\{\vec{x} , f(\vec{x})\} | \alpha)$ the probability a given pixel is in phase $\alpha$ given we know it's position and value (what we are trying to estimate)
- $P(\alpha)$ probability of any pixel in an image being part of the phase (expected volume fraction of that phase)
- $P(I(\vec{x}) | \alpha)$ probability adjustment based on knowing the value of $I$ at the given point (standard threshold)
- $P(f(\vec{x^{\prime}}) | \alpha)$ are the collective probability adjustments based on knowing the value of a pixels neighbors (very simple version of [Markov Random Field](http://en.wikipedia.org/wiki/Markov_random_field) approaches)
Contouring
===
Expanding on the hole filling issues examined before, a general problem in imaging is identifying regions of interest with in an image.
- For samples like brains it is done to identify different regions of the brain which are responsible for different functions.
- In material science it might be done to identify a portion of the sample being heated or understress.
- There are a number of approaches depending on the clarity of the data and the
Convex Hull Approach
===
takes all of the points in a given slice or volume and finds the smallest convex 2D area or 3D volume (respectively) which encloses all of those points.
 ***
Depending on the type of sample the convex hull can make sense for filling in the gaps and defining the boundaries for a sample.
***
Depending on the type of sample the convex hull can make sense for filling in the gaps and defining the boundaries for a sample.
 The critical short coming is it is very sensitive to single outlier points.
The critical short coming is it is very sensitive to single outlier points.
 Convex Hull Example
===
The convex hull very closely matches the area we would define as 'bone' without requiring any parameter adjustment, resolution specific adjustments, or extensive image-processing, for such a sample a convex hull is usually sufficient.
Convex Hull Example
===
The convex hull very closely matches the area we would define as 'bone' without requiring any parameter adjustment, resolution specific adjustments, or extensive image-processing, for such a sample a convex hull is usually sufficient.
 ***
Here is an example of the convex hull applied to a region of a cortical bone sample. The green shows the bone and the red shows the convex hull. Compared to a visual inspection, the convex hull overestimates the bone area as we probably would not associate the region where the bone curves to the right with 'bone area'
***
Here is an example of the convex hull applied to a region of a cortical bone sample. The green shows the bone and the red shows the convex hull. Compared to a visual inspection, the convex hull overestimates the bone area as we probably would not associate the region where the bone curves to the right with 'bone area'
 ***
Rubber Band
===
***
Rubber Band
===
 ***
***

 Rubber Band: More flexible constraints
===
If we use quartiles or the average instead of the maximum value we can make the method less sensitive to outlier pixels
Rubber Band: More flexible constraints
===
If we use quartiles or the average instead of the maximum value we can make the method less sensitive to outlier pixels
 Contouring: Manual - Guided Methods
===
Many forms of guided methods exist, the most popular is known simply as the _Magnetic Lasso_ in Adobe Photoshop ([video](http://people.ee.ethz.ch/~maderk/videos/MagneticLasso.swf)).
The basic principal behind many of these methods is to optimize a set of user given points based on local edge-like information in the image. In the brain cortex example, this is the small gradients in the gray values which our eyes naturally seperate out as an edge but which have many gaps and discontinuities.
[Active Contours / Snakes](http://link.springer.com/article/10.1007%2FBF00133570#page-1)
Beyond
===
- A multitude of other techniques exist for classifying groups and courses in Data Science and Artificial Intelligence go into much greater details.
- These techniques are generally underused because they are complicated to explain and robustly test and can arouse suspicion from reviewers.
- Because of their added complexity it is easier to manipulate these methods to get desired results from almost any dataset
- But if the approach is based on a physical model of the images and the underyling system it is acceptable
- Additionally they usually require some degree of implementation (coding).
Fuzzy Classification
===
Fuzzy classification based on [Fuzzy logic](http://en.wikipedia.org/wiki/Fuzzy_logic) and [Fuzzy set theory](http://www.academia.edu/4978200/Applications_of_Fuzzy_Set_Theory_and_Fuzzy_Logic_in_Image_Processing) and is a general catagory for multi-value logic instead of simply __true__ and __false__ and can be used to build __IF__ and __THEN__ statements from our probabilistic models.
### Instead of
$$P(\{\vec{x} , I(\vec{x})\} | \alpha) \propto P(\alpha) + P(I(\vec{x}) | \alpha)+$$
$$P(\sum_{x^{\prime} \in \mathcal{N}} I(\vec{x^{\prime}}) | \alpha)$$
***
### Clear simple rules
which encompass aspects of filtering, thresholding, and morphological operations
- __IF__ the intensity if dark ($<100$)
- __AND__ a majority of the neighborhood ($\mathcal{N}$) values are dark ($<100$)
- __THEN__ it is a cell

Contouring: Manual - Guided Methods
===
Many forms of guided methods exist, the most popular is known simply as the _Magnetic Lasso_ in Adobe Photoshop ([video](http://people.ee.ethz.ch/~maderk/videos/MagneticLasso.swf)).
The basic principal behind many of these methods is to optimize a set of user given points based on local edge-like information in the image. In the brain cortex example, this is the small gradients in the gray values which our eyes naturally seperate out as an edge but which have many gaps and discontinuities.
[Active Contours / Snakes](http://link.springer.com/article/10.1007%2FBF00133570#page-1)
Beyond
===
- A multitude of other techniques exist for classifying groups and courses in Data Science and Artificial Intelligence go into much greater details.
- These techniques are generally underused because they are complicated to explain and robustly test and can arouse suspicion from reviewers.
- Because of their added complexity it is easier to manipulate these methods to get desired results from almost any dataset
- But if the approach is based on a physical model of the images and the underyling system it is acceptable
- Additionally they usually require some degree of implementation (coding).
Fuzzy Classification
===
Fuzzy classification based on [Fuzzy logic](http://en.wikipedia.org/wiki/Fuzzy_logic) and [Fuzzy set theory](http://www.academia.edu/4978200/Applications_of_Fuzzy_Set_Theory_and_Fuzzy_Logic_in_Image_Processing) and is a general catagory for multi-value logic instead of simply __true__ and __false__ and can be used to build __IF__ and __THEN__ statements from our probabilistic models.
### Instead of
$$P(\{\vec{x} , I(\vec{x})\} | \alpha) \propto P(\alpha) + P(I(\vec{x}) | \alpha)+$$
$$P(\sum_{x^{\prime} \in \mathcal{N}} I(\vec{x^{\prime}}) | \alpha)$$
***
### Clear simple rules
which encompass aspects of filtering, thresholding, and morphological operations
- __IF__ the intensity if dark ($<100$)
- __AND__ a majority of the neighborhood ($\mathcal{N}$) values are dark ($<100$)
- __THEN__ it is a cell
