
1. Revision History
hOCR has been originally developed by Thomas Breuel.
See the releases and full commit history for a revision history.
2. Introduction
The purpose of this document is to define an open standard for representing document layout analysis and OCR results as a subset of HTML. The goal is to reuse as much existing technology as possible, and to arrive at a representation that makes it easy to store, share, process and display OCR results.
This specification defines many features that can represent a variety of OCR-related information. However, being built on top of HTML, hOCR is designed to make it easy to start simple and gradually use more complex constructs when necessary.
Consider you have an HTML document that encodes a book: Wrapping page elements
in [<div class="ocr_page">](#ocr_page) tags will convey the page boundaries to
hOCR-capable agents and turn the HTML document into an hOCR document.
3. Terminology and Representation
This document describes a representation of various aspects of OCR output in an XML-like format. That is, we define as set of tags containing text and other tags, together with attributes of those tags. However, since the content we are representing is formatted text,
However, we are not actually using a new XML for the representation; instead embed the representation in XHTML (or HTML) because [XHTML1] and XHTML processing already define many aspects of OCR output representation that would otherwise need additional, separate and ad-hoc definitions. These aspects include:
-
standard representations for common logical structuring elements, including section headings, citations, tables, emphasis, line breaks, quotations, citations, and preformatted text
-
standard representations for fonts, embedded images, embedded vector graphics, tables, languages, writing direction, colors
-
standard representations for geometric layout and positioning
-
output files that are understood without any further modification by widely used viewers (browsers), editors, conversion tools, and indexing tools
-
libraries for parsing and generating the content
-
support for document metadata
We are embedding this information inside HTML by encoding it within valid tags and attributes inside HTML; We are going to use the terms "elements" and "properties" for referring to embedded markup.
Specify that class must be a single value
Elements are defined by the class= attribute on an arbitrary HTML tag. All
elements in this format have a class name of the form ocr..._....
Properties are defined by putting information into the title= attribute of an
HTML tag. Properties in title attributes are of the form “name values...”, and
multiple properties are separated by semicolons.
<div class="ocr_page" id="page_1"> <div class="ocr_carea" id="column_2" title="bbox 313 324 733 1922"> <div class="ocr_par" id="par_7"> ... </div> <div class="ocr_par" id="par_19"> ... </div> </div> </div>
3.1. General Properties
The following properties can apply to most elements (where it makes sense):
3.1.1. bbox
bbox x0 y0 x1 y1
The bbox - short for "bounding box" - of an element is a rectangular box
around this element, which is defined by the upper-left corner (x0, y0) and
the lower-right corner (x1, y1).
-
the values are with reference to the the top-left corner of the document image and measured in pixels
-
the order of the values are
x0 y0 x1 y1= "left top right bottom" -
use x_bboxes below for character bounding boxes
-
do not use bbox unless the bounding box of the layout component is, in fact, rectangular
-
some non-rectangular layout components may have rectangular bounding boxes if the non-rectangularity is caused by floating elements around which text flows
See also the section §5.2.1 bbox (typesetting).
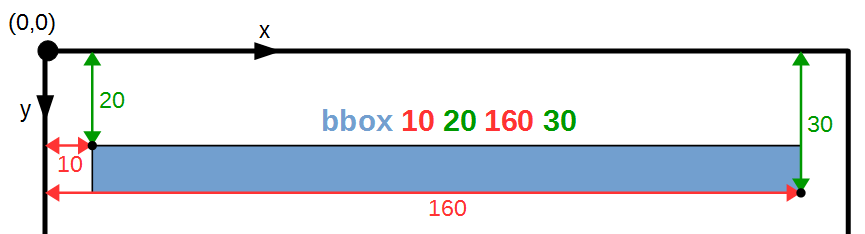
<span class='ocr_line' id='line_1' title="bbox 10 20 160 30">...</span>
The bounding box bbox of this line is shown in blue and it is span
by the upper-left corner (10, 20) and the lower-right corner (160, 30).
All coordinates are measured with reference to the top-left corner of
the document image which border is drawn in black.
3.1.2. textangle
textangle alpha
The angle in degrees by which textual content has been rotate relative to the rest of the page (if not present, the angle is assumed to be zero); rotations are counter-clockwise, so an angle of 90 degrees is vertical text running from bottom to top in Latin script; note that this is different from reading order, which should be indicated using standard HTML properties
3.2. Non-recommended general properties
The following properties can apply to most elements but should not be used unless there is no alternative:
3.2.1. poly
poly x0 y0 x1 y1 ...
A closed polygon for elements with non-rectangular bounds
-
this property must not be used unless there is no other way of representing the layout of the page using rectangular bounding boxes, since most tools will simply not have the capability of dealing with non-rectangular layouts
-
note that the natural and correct representation of many non-rectangular layouts is in terms of rectangular content areas and rectangular floats
-
documents using polygonal borders anywhere must indicate this by adding ocrp_poly to the list of ocr-capabilities (see §12.1 Capabilities)
-
documents should attempt to provide a reasonable bbox equivalent as well
3.2.2. order
order n
The reading order of the element (an integer)
-
this property must not be used unless there is no other way of representing the reading order of the page by element ordering within the page, since many tools will not be able to deal with content that is not in reading order
3.2.3. presence
presence presence must be declared in the document meta data
3.2.4. cflow
cflow s
This property relates the flow between multiple ocr_carea elements,
and between ocr_carea and ocr_linear elements.
The content flow on the page that this element is a part of
-
s must be a unique string for each content flow
-
must be present on
ocr_careaandocrx_blocktags when reading order is attempted and multiple content flows are present -
presence must be declared in the document meta data
3.2.5. baseline
baseline pn pn-1 ... p0
This property applies primarily to textlines.
The baseline is described by a polynomial of order n with the coefficients pn ... p0 with n = 1 for a linear (i.e. straight) line.
The polynomial is in the coordinate system of the line, with the bottom left of the bounding box as the origin.
The hOCR output for the first line of eurotext.tif contains the following information:
<span class='ocr_line' id='line_1_1' title="bbox 105 66 823 113; baseline 0.015 -18">...</span>
bbox is the bounding box of the line in image coordinates (blue). The two
numbers for the baseline are the slope (1st number) and constant term (2nd
number) of a linear equation describing the baseline relative to the bottom
left corner of the bounding box (red). The baseline crosses the y-axis at -18 and its slope angle is arctan(0.015) = 0.86°.

4. Logical Structuring Elements
The classes defined in this section for logically structuring a hOCR document have their standard meaning as used in the publishing industry and tools like LaTeX, MS Word, and others.
Elements with these classes should use the recommended HTML tag given below. This is entirely optional, it may not be possible or desirable to actually choose those tags (e.g., when adding hOCR information to an existing HTML output routine).
-
ocr_document
-
Recommended HTML Tag:
div -
ocr_title
-
Recommended HTML Tag: h1
-
ocr_author
ocr_abstract
ocr_part
-
Recommended HTML Tag:
h1 -
ocr_chapter
-
Recommended HTML Tag:
h1 -
ocr_section
-
Recommended HTML Tag:
h2 -
ocr_subsection
-
Recommended HTML Tag:
h3 -
ocr_subsubsection
-
Recommended HTML Tag:
h4 -
ocr_display
ocr_blockquote
-
Recommended HTML Tag:
blockquote -
ocr_par
-
Recommended HTML Tag:
p -
ocr_linear
ocr_caption
-
Image captions may be indicated using the
ocr_captionelement; such an element refers to the image(s) contained within the same float, or the immediately adjacent image if both the image and theocr_captionelement are in running text.
Tags must be nested as indicated by the following list, but not all tags within the hierarchy need to be present.
For all of these elements except ocr_linear, there exists a natural linear
ordering defined by reading order (ocr_linear indicates that the elements
contained in it have a linear ordering). At the level of ocr_linear, there
may not be a single distinguished order. A common example of ocr_linear is a
newspaper, in which a single newspaper may contain many linear, but there is no
unique reading order for the different linear. OCR evaluation tools should
therefore be sensitive to the order of all elements other than ocr_linear.
Textual information like section numbers and bullets must be represented as text inside the containing element.
Documents whose logical structure does not map naturally onto these logical structuring elements must not use them for other purposes.
5. Typesetting Related Elements
The following typesetting related elements are based on a typesetting model as found in most typesetting systems, including XSL:FO, (La)TeX, LibreOffice, and Microsoft Word.
In those systems, each page is divided into a number of areas. Each area can either be a part of the body text (or multiple body texts, in the case of newspaper layouts). The content of the areas derives from a linear stream of textual content, which flows into the areas, filling them linewise in their preferred directions.
Overlayed onto the page is a set of floating elements; floating elements exist outside the normal reading order. Floating elements may be introduced by the textual content, or they may be related to the page itself (anchoring is a logical property). In typesetting systems, floating elements may be anchored to the page, to paragraphs, or to the content stream. Floating elements can overlap content areas and render on top of or under content, or they can force content to flow around them. The default for floating elements in this spec is that their anchor is undefined (it is a logical property, not a typesetting property), and that text flows around them. Note that with rectangular content areas and rectangular floats, already a wide variety of non-rectangular text shapes can be realized.
There is currently no way of indicating anchoring or flow-around properties for floating elements; properties need to be defined for this.
5.1. Classes for typesetting elements
The following classes, as well as floats are used for type-setting elements.
5.1.1. ocr_page
The ocr_page element must be present in all hOCR documents.
5.1.2. ocr_column
5.1.3. ocr_carea
"ocr content area" or "body area"
Used to be called
ocr_column
The ocr_carea elements should appear in reading order unless this is impossible
because of some other structuring requirement. If the document contains multiple ocr_linear streams, then each ocr_carea must indicate which stream it belongs
to.
Note that for many documents, the actual ground truth careas are well-defined
by the document style of the original document before printing and scanning.
From a single page, the careas of the original document style cannot be
recovered exactly. However, the partition of a document by ocr_carea for an
individual page shall be considered correct relative to ground truth if
-
all the text contained in a ground truth carea is fully contained within a single
ocr_carea, -
no text outside a ground truth
careais contained within anocr_carea, and -
the
ocr_careaappear in the same order as the text flow relationships between the ground truth careas.
5.1.4. ocr_line
In typesetting systems, content areas are filled with “blocks”, but most of
those blocks are not recoverable or semantically meaningful. However, one type
of block is visible and very important for OCR engines: the line. Lines are
typesetting blocks that only contain glyphs (“inlines” in XSL terminology).
They are represented by the ocr_line area.
ocr_line should be in a <span>
5.1.5. ocr_separator
Any separator or similar element
5.1.6. ocr_noise
Any noise element that isn’t part of typesetting
5.2. Recommended Properties for typesetting elements
The following properties should be present:
5.2.1. bbox (typesetting)
The bounding box of the page; for pages, the top left corner must be at (0,0), so a typical page bounding box will look like bbox 0 0 2300 3200
5.2.2. image
image imagefile
-
image file name used as input
-
syntactically, must be a UNIX-like pathname or http URL (no Windows pathnames)
-
may be relative
-
cannot be resolved to the actual file in general (e.g., if the hOCR file becomes separated from the image file)
-
if the hOCR file is present in a directory hierarchy or file archive, should resolve to the corresponding image file
5.2.3. imagemd5
imagemd5 checksum
-
MD5 fingerprint of the image file that this page was derived from
-
allows re-associating pages with source images
5.2.4. ppageno
ppageno n
-
the physical page number
-
the front cover is page number 0
-
should be unique
-
must not be present unless the pages in the document have a physical ordering
-
must not be present unless it is well defined and unique
5.2.5. lpageno
lpageno string
-
the logical page number expressed on the page
-
may not be numerical (e.g., Roman numerals)
-
usually is unique
-
must not be present unless it has been recognized from the page and is unambiguous
5.3. Optional Properties for typesetting elements
The following properties MAY be present:
5.3.1. scan_res
scan_res x_res y_res
-
scanning resolution in DPI
5.3.2. x_scanner
x_scanner string
-
a representation of the scanner
5.3.3. x_source
x_source string
-
an implementation-dependent representation of the document source
-
could be a URL or a /gfs/ path
-
offsets within a multipage format (e.g., TIFF) may be represented using additional strings or using URL parameters or fragments
-
examples
-
x_source /gfs/cc/clean/012345678911 17 -
x_source http://pageserver/012345678911&page=17
-
In addition to the standard
properties, the ocr_line area supports the following additional properties:
5.3.4. hardbreak
hardbreak n
-
a zero (default) indicates that the end of the line is not a hard (explicit) line break, but a break due to text flow
-
a one indicates that the line is a hard (explicit) line break
Any special characters representing the desired end-of-line processing must be
present inside the ocr_line element. Examples of such special characters are a
soft hyphen ("", U+00AD), a hard line break (<br>), or whitespace () for soft
line breaks.
5.4. Classes for floats
Floats should not be nested.
The following floats are defined:
5.4.1. ocr_float
ocr_float
5.4.2. ocr_separator
ocr_separator in the context of float classes.
5.4.3. ocr_textfloat
ocr_textfloat
5.4.4. ocr_textimage
ocr_textimage
5.4.5. ocr_image
ocr_image
5.4.6. ocr_linedrawing
Something that could be represented well and naturally in a vector graphics format like SVG (even if it is actually represented as PNG)
5.4.7. ocr_photo
Something that requires JPEG or PNG to be represented well
5.4.8. ocr_header
ocr_header
5.4.9. ocr_footer
ocr_footer
5.4.10. ocr_pageno
ocr_pageno
5.4.11. ocr_table
ocr_table
6. Inline Representations
There is some content that should behave and flow like text
6.1. Classes for Inline Representation
6.1.1. ocr_glyph
An individual glyph represented as an image (e.g., an unrecognized character)
Must contain a single <img> tag, or be present on one
6.1.2. ocr_glyphs
Multiple glyphs represented as an image (e.g., an unrecognized word)
Must contain a single <img> tag, or be present on one
6.1.3. ocr_dropcap
An individual glyph representing a dropcap
May contain text or an <img> tag; the alt of the image tag should contain
the corresponding text
6.1.4. ocr_chem
A chemical formula
Must contain either a single <img> tag or [CML] markup, or be present on
one
6.1.5. ocr_math
A mathematical formula
Must contain either a single <img> tag or [MathML] markup, or be present on
one
Mathematical and chemical formulas that float must be put into an ocr_float section.
Mathematical and chemical formulas that are “display” mode should be put into
an ocr_display section.
6.1.6. Superscript and Subscript
Superscripts and subscripts, when not in ocr_math or ocr_chem formulas,
must be represented using the HTML <sup> and <sub> tags, even if special
Unicode characters are available.
6.1.7. Non-breaking space
Non-breaking spaces must be represented using the HTML entity.
6.1.8. Non-default spaces
Different space widths should be indicated using HTML and  , &emsp,  , ‌, ‍.
6.1.9. Hyphenation
Soft hyphens must be represented using the HTML ­ entity.
The HTML ‎ and ‏ entities (indicating writing direction) must not be used; all
writing direction changes must be indicated with tags.
6.1.10. Ruby characters
Furigana and similar constructs must be represented using their correct Unicode encoding.
7. Character Information
7.1. Classes for Character Information
Character-level information may be put on any element that contains only a single "line" of text.
7.1.1. ocr_cinfo
If no other layout element applies, the ocr_cinfo element may be used.
7.2. Properties for Character Information
7.2.1. cuts
cuts c1 c2 c3 ...
-
character segmentation cuts (see below)
-
there must be a bbox property relative to which the cuts can be interpreted
7.2.2. nlp
nlp c1 c2 c3 ...
-
estimate of the negative log probabilities of each character by the recognizer
For left-to-write writing directions, cuts are sequences of deltas in the x and y direction; the first delta in each path is an offset in the x direction relative to the last x position of the previous path. The subsequent deltas alternate between up and right moves.
Assume a bounding box of (0,0,300,100); then
cuts("10 11 7 19") = [ [(10,0),(10,100)], [(21,0),(21,100)], [(28,0),(28,100)], [(47,0),(47,100)] ] cuts("10,50,3 11,30,-3") = [ [(10,0),(10,50),(13,50),(13,100)], [(21,0),(21,30),(18,30),(18,100)] ]
<span class="ocr_cinfo" title="bbox 0 0 300 100; nlp 1.7 2.3 3.9 2.7; cuts 9 11 7,8,-2 15 3">hello</span>
Cuts are between all codepoints contained within the element, including any whitespace and control characters. Simply use a delta of 0 (zero) for invisible codepoints.
Writing directions other than left-to-right specify cuts as if the bounding box for the element had been rotated by a multiple of 90 degrees such that the writing direction is left to right, then rotated back.
It is undefined what happens when cut paths intersect, with the exception that a delta of 0 always corresponds to an invisible codepoint.
8. OCR Engine-Specific Markup
A few abstractions are used as intermediate abstractions in OCR engines, although they do not have a meaning that can be defined either in terms of typesetting or logical function. Representing them may be useful to represent existing OCR output, say for workflow abstractions.
Common suggested engine-specific markup are:
8.1. Classes for engine specific markup
8.1.1. ocrx_block
-
any kind of "block" returned by an OCR system
-
engine-specific because the definition of a "block" depends on the engine
8.1.2. ocrx_line
-
any kind of "line" returned by an OCR system that differs from the standard
ocr_lineabove -
might be some kind of "logical" line
8.1.3. ocrx_word
-
any kind of "word" returned by an OCR system
-
engine specific because the definition of a "word" depends on the engine
The meaning of these tags is OCR engine specific. However, generators should attempt to ensure the following properties:
-
An
ocrx_blockshould not contain content from multipleocr_carea. -
The union of all
ocrx_blocksshould approximately cover allocr_carea. -
an
ocrx_blockshould contain either a float or body text, but not both -
an
ocrx_blockshould contain either an image or text, but not both -
an
ocrx_lineshould correspond as closely as possible to anocr_line -
ocrx_cinfoshould nest insideocrx_line -
ocrx_cinfoshould contain only x_confs, x_bboxes, and cuts attributes
8.2. Properties for engine-specific markup
The following properties are defined:
8.2.1. x_font
x_font s
-
OCR-engine specific font names
8.2.2. x_fsize
x_fsize n
-
OCR-engine specific font size
8.2.3. x_bboxes
x_bboxes b1x0 b1y0 b1x1 b1y1 b2x0 b2y0 b2x1 b2y1 ...
-
OCR-engine specific boxes associated with each codepoint contained in the element
-
note that the bbox property is a property for the bounding box of a layout element, not of individual characters
-
in particular, use
<span class="ocr_cinfo" title="x_bboxes ....">, not<span class="ocr_cinfo" title="bbox ...">
8.2.4. x_confs
x_confs c1 c2 c3 ...
-
OCR-engine specific character confidences
-
c1etc. must be numbers -
higher values should express higher confidences
-
if possible, convert character confidences to values between 0 and 100 and have them approximate posterior probabilities (expressed in %)
8.2.5. x_wconf
x_wconf n
-
OCR-engine specific confidence for the entire contained substring
-
n must be a number
-
higher values should express higher confidences
-
if possible, convert word confidences to values between 0 and 100 and have them approximate posterior probabilities (expressed in %)
9. Font, Text Color, Language, Direction
OCR-generated font and text color information is encoded using standard HTML
and CSS attributes on elements with a class of ocr_... or ocrx_....
Language and writing direction should be indicated using the HTML standard
attributes lang= and dir=, or alternatively can be indicated as properties on
elements.
OCR information and presentation information can be separated by putting the
CSS info related to the CSS in an outer element with an ocr_ or ocrx_ class,
and then overriding it for the presentation by nesting another <span> with the
actual presentation information inside that:
<span class="ocr_cinfo" style="ocr style"><span style="presentation style"> ... </span></span>
The CSS3 text layout attributes can be used when necessary. For example, CSS supports writing-mode, direction, glyph-orientation [ISO15924]-based script (list of codes), text-indent, etc.
10. Alternative Segmentations / Readings
Alternative segmentations and readings are indicated by a <span> with class="alternatives". It must contains <ins> and <del> elements. The first
contained element should be <ins> and represent the most probable interpretation,
the subsequent ones <del>. Each <ins> and <del> element should have class="alt" and a
property of either nlp or x_cost. These <span>, <ins>, and <del> tags can nest
arbitrarily.
<span class="alternatives"> <ins class="alt" title="nlp 0.3">hello</ins> <del class="alt" title="nlp 1.1">hallo</del> </span>
Whitespace within the <span> but outside the contained <ins>/<del> elements is ignored and should be inserted to improve readability of the HTML
when viewed in a browser.
11. Grouped Elements and Multiple Hierarchies
The different levels of layout information (logical, physical, engine-specific)
each form hierarchies, but those hierarchies may not be mutually compatible;
for example, a single ocr_page may contain information from multiple sections
or chapters. To represent both hierarchies within a single document, elements
may be grouped together. That is, two elements with the same class may be
treated as one element by adding a "groupid identifier" property to them and
using the same identifier.
Grouped elements should be logically consistent with the markup they represent; for example, it is probably not sensible to use grouped elements to interleave parts of two different chapters. Therefore, grouped elements should usually be adjacent in the markup.
Applications using hOCR may choose to manipulate grouped elements directly, but
the simplest way of dealing with them is to transform a document with grouped
elements into one without grouped elements prior to further processing by first
removing tags that are not of interest for the subsequent processing step, and
then collapsing grouped elements into single elements. For example, output
that contains both logical and physical layout information, where the logical
layout information uses grouped elements, can be transformed by removing all
the physical layout information, and then collapsing all split ocr_chapter elements into single ocr_chapter elements based on the groupid. The result is
a simple DOM tree. This transformation can be provided generically as a
pre-processor or Javascript.
The presence of grouped elements does not need to be indicated in the header; when it affects their operations, hOCR processors should check for the presence of grouped elements in the output and fail with an error message if they cannot correctly process the hOCR information.
12. Metadata
The creator of the hOCR document can indicate the following information
information using meta tags in the head section.
-
ocr-system
-
Indicates software and version that generated the hOCR document
Every hOCR document must have exactly one ocr-system metadata field
-
ocr-capabilities
-
Features consumers of the hOCR document can expect
See §12.1 Capabilities for possible values
Every hOCR document must have exactly one ocr-capabilities metadata field
-
The number of
ocr_pagein the document -
Use ISO 639-1 codes
Value may be
unknown -
Use ISO 15924 letter codes
Value may be
unknown
12.1. Capabilities
Any program generating files in this output format must indicate in the document metadata what kind of markup it is capable of generating. This includes listing the exact set of markup sections that the system could have generated, even if it did not actually generate them for the particular document.
If a document lists a certain capabilities but no element or attribute is found that corresponds to that capability, users of the document may infer that the content is absent in the source document. If a capability is not listed, the corresponding element or attribute must not be present in the document.
The capability to generate specific properties is given by the prefix ocrp_...;
the important properties are:
-
ocrp_lang
-
Capable of generating
lang=attributes -
Capable of generating
dir=attributes -
ocrp_poly
-
Capable of generating polygonal bounds
-
ocrp_font
-
Capable of generating font information (standard font information)
-
Capable of generating nlp confidences
-
ocr_embeddedformat_<formatname> -
The capability to generate other specific embedded formats is given by the prefix
ocr_embeddedformat_<formatname>. -
ocr_<tag>_unordered -
If an OCR engine represents a particular tag but cannot determine reading order for that tag, it must must specify a capability of
ocr_<tag>_unordered.
12.2. Document metadata
For document meta information, use the Dublin Core Embedding into HTML. See also Citation Guidelines for Dublin Core.
12.3. Example
<html> <head> <meta name="ocr-system" content="tesseract v3.03"/> <meta name="ocr-capabilities" content="ocr_page ocr_line ocrp_lang"/> <meta name="ocr-langs" content="aa la zu"/> <meta name="ocr-scripts" content="Arab Khmr"/> <meta name="ocr-number-of-pages" content="112"/> ... </head> ... </html>
Indicate that the work this hOCR file represents:
13. Profiles
hOCR provides standard means of marking up information, but it does not mandate the presence or absence of particular kinds of information. For example, an hOCR file may contain only logical markup, only physical markup, or only engine-specific markup. As a result, merely knowing that OCR output is hOCR compliant doesn’t tell us whether that file is actually useful for subsequent processing.
OCR systems can use hOCR in various different ways internally, but we will eventually define some common profiles that mandate what kinds of information needs to be present in particular kinds of output.
Of particular importance are:
-
physical layout profile: OCR output in XHTML format with a defined set of common physical layout markup capabilities (page, carea, floats, line). Logical layout may be present as well, but the document tree structure must represent the physical layout structure, with logical layout elements split and grouped as needed.
-
logical layout profile: OCR output in XHTML format with a defined set of common logical layout markup capabilities (linear, chapter, section, subsection). Physical layout may be present as well, but the document tree structure must represent the logical layout structure, with logical layout elements split and grouped as needed.
Other possible profiles might be defined for specific engines or specific document classes:
-
common commercial OCR output (e.g., Abbyy)
-
book target
-
all logical structuring elements (as applicable), except
ocr_linear
-
-
newspaper target
-
all logical structuring elements (as applicable)
-
articles map on
ocr_linear
-
14. HTML Markup
The HTML-based markup is orthogonal to the hOCR-based markup; that is, both can
be chosen independent of one another. The only thing that needs to be
consistent between the two markups is the text contained within the tags. hOCR
and other embedded format tags can be put on HTML tags, or they can be put on
their own div/span tags.
There are many different choices possible and reasonable for the HTML markup, depending on the use and further processing of the document. Each such choice must be indicated in the meta data for the document.
Many mappings derived from existing tools are quite similar, and most follow the restrictions and recommendations below already without further modifications.
Depending on the particular HTML markup used in the document, the document is suitable for different kinds of processing and use. The formats have the following intents:
-
Straightforward equivalent of Goodoc or [XDOC]
-
Target format for convenient on-line viewing and intermediate format for indexing
-
Target format for layout-preserving on-screen document viewing
-
Formats defined in §14.5 HTML produced by OCR engines
-
Straightforward recording of commercial OCR system output
-
Formats defined in §14.6 HTML with absolute positioning
-
Target format for services like Google’s View as HTML
As long as a format contains the hOCR information, it can be reprocessed by layout analysis software and converted into one of the other formats. In particular, we envision layout analysis tools for converting any hOCR document into html_absolute, html_xytable_absolute, and html_simple. Furthermore, internally, a layout analysis system might use html_xytable_absolute as an intermediate format for converting hOCR into html_simple.
14.1. Restrictions on HTML Content
To avoid problems, any use of HTML markup must follow the following rules:
-
HTML content must not use class names that conflict with any of those defined in this document (
ocr_*) -
HTML content must not use the title= attribute on any element with an ocr_* class for any purposes other than encoding OCR-related properties as described in this document
14.2. Recommendations for Mappings
When possible, any mapping of logical structure onto HTML should try to follow the following rules:
-
the mapping should be "natural" -- similar to what an author of the document might have entered into a WYSIWYG content creation tool
-
text should be in reading order
-
all tags should be used for the intended purpose (and only for the intended purpose) as defined in the [HTML40] spec.
-
floats are contained in
divelements with astylethat includes a float attribute -
repeating floating page elements (header/footer) should be repeated and occur in their natural location in reading order (e.g., between pages)
-
embedded images and SVG should be contained in files in the same directory (no
/in the URL) and embedded withimgandembedtags, respectively
Specifically
-
emandstrongshould represent emphasis, and are preferred tob,i, andu -
b,i, andushould represent a change in the corresponding attribute for the current font (but an OCR font specification must still be given) -
pshould represent paragraph breaks -
brshould represent explicit linebreaks (not linebreak that happen because of text flow) -
h1, ...,h6should represent the logical nesting structure (if any) of the document -
ashould represent hyperlinks and references within the document -
blockquoteshould represent indented quotations, but not other uses of indented text. -
tableshould represent tables, including correct use of thethtag
If necessary, the markup may use the following non-standard tags:
-
nobrto indicate that line breaking is not permitted for the enclosed content -
wbrto indicate that line breaking is permitted at that location
14.3. HTML without logical markup
The html_none format contains no logical markup at all; it is
simply a collection of div and span elements with associated hOCR
information. Note that such documents can still be rendered visually through
the use of CSS.
14.4. HTML with limited logical elements
The html_simple format follows the restrictions and recommendations above, and only uses the following tags:
-
b,i, andufor appearance changes (bold, italic, underline) -
fontfor any other appearance changes -
divwith a float style for floats -
tablefor tables -
imgfor images -
all SVG must be externally embedded with the
embedtag -
the use of other embedded formats is permitted
-
all other uses of
div,span,ins, anddelonly for hOCR tags or other embedded formats (hCard, …)
14.5. HTML produced by OCR engines
HTML markup produced by default by the OCR engine for the given document
must follow the template html_ocr_<engine>.
Examples of possible values are:
-
The HTML was generated by some OCR engine, but it’s unknown which one
-
14.6. HTML with absolute positioning
-
html_absolute
-
The HTML represents absolute positioning of elements on each page.
Possible subformats are:
-
absolute positioning of cols
-
absolute positioning of paragraphs
-
html_absolute_lines
-
absolute positioning of lines
-
absolute positioning of words
-
absolute positioning of characters
The "View as HTML" for PDF files feature of Google Search uses html_absolute_lines; this is probably the most reasonable choice for approximating the appearance of the original document.
14.7. HTML as table
-
The HTML is a table that gives the XY-cut layout segmentation structure of the page in tabular form.
Note that in this format, text order does not necessarily correspond to reading order.
The format must contain one
tableof class ocr_xycut representing each page. The markup of the content of the table itself is as in html_simple.
Possible subformats are:
-
html_xytable_absolute
-
The
tablestructure must represent the absolute size of the original page element. -
html_xytable_relative
-
Table element sizes are expressed relative (percentages).
14.8. HTML from word processors
The HTML represents markup that follows the mappings of the given document processor to HTML.
Note that the document doesn’t actually need to have been constructed in the processor and that the processor doesn’t need to have been used to generate the HTML. For example, the html_latex2html tag merely indicates that, say, a scanned and ocr’ed article uses the same conventions for logical markup tags that an equivalent article actually written in LaTeX and actually converted to HTML would have used.
-
html_latex2html
-
HTML mapping generated by “Save As HTML”
-
HTML mapping generated by “Save As HTML”
-
HTML mapping generated by official XSL style sheets
15. Sample Usage
See also the hocr-tools for more samples.
The HTML format described here may seem fairly complicated and difficult to parse, but because there are lots of tools for manipulating HTML documents, they’re actually pretty easy to manipulate. Here are some examples:
import libxml2,re,os,string # convert the HTML to XHTML (if necessary) os.system("tidy -q -asxhtml < page.html > page.xhtml 2> /dev/null") # parse the XML doc = libxml2.parseFile('page.xhtml') # search all nodes having a class of ocr_line lines = doc.xpathEval("//*[@class='ocr_line']") # a function for extracting the text from a node def get_text(node): textnodes = node.xpathEval(".//text()") s = string.join([node.getContent() for node in textnodes]) return re.sub(r'\s+',' ',s) # a function for extracting the bbox property from a node # note that the title= attribute on a node with an ocr_ class must # conform with the OCR spec def get_bbox(node): data = node.prop('title') bboxre = re.compile(r'\bbbox\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)') return [int(x) for x in bboxre.search(data).groups()] # this extracts all the bounding boxes and the text they contain # it doesn’t matter what other markup the line node may contain for line in lines: print get_bbox(line),get_text(line)
Note that the OCR markup, basic HTML markup, and semantic markup can co-exist within the same HTML file without interfering with one another.
16. IANA Considerations
16.1. Media Type
In accordance to [RFC2048]
-
MIME media type name
-
text -
MIME subtype name:
-
vnd.hocr+html -
Required parameters:
Optional parameters:
Encoding considerations:
-
hOCR documents should be encoded as UTF-8
-
Security considerations:
Interoperability considerations:
Applications which use this media type:
File extension(s):
-
*.html,*.hocr