|
|
|
|
|
Semantic Attention
|
Torch Implementation of You et al. CVPR 2016 Image Captioning with Semantic Attention |
|
|
Adaptive Attention
|
Implementation of "Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning" https://arxiv.org/abs/1612.01887 with Torch. |
|
|
Show, Attend & Tell
|
Source code for Show, Attend and Tell: Neural Image Caption Generation with Visual Attention runnable on GPU and CPU. Implemented in Theano |
|
|
neuraltalk2.torch
|
Efficient Image Captioning code in Torch, runs on GPU And the base for so many captioning codes |
|
|
neuraltalk2.pytorch
|
image captioning model in pytorch(finetunable cnn in
branch "with_finetune") |
|
|
LRCN
|
Long-term Recurrent Convolutional Networks |
|
|
vqa-winner-cvprw-2017.pytorch
|
2017 VQA Challenge Winner (CVPR'17 Workshop). Pytorch
implementation of Tips and Tricks for Visual Question
Answering: Learnings from the 2017 Challenge by Teney et
al. |
 |
|
self-critical.pytorch
|
Unofficial pytorch implementation for Self-critical
Sequence Training for Image Captioning |
|
|
order-embedding-disc.theano<=""
a="">
|
Implementation of caption-image retrieval from the
paper "Order-Embeddings of Images and Language" |
|
|
visual-semantic-embedding.theano<="" a="">
|
Code for the image-sentence ranking methods from
"Unifying Visual-Semantic Embeddings with Multimodal
Neural Language Models" (Kiros, Salakhutdinov, Zemel.
2014). |
|
|
multimodal_word2vec.chainer
|
implementation of Combining Language and Vision with
a Multimodal Skip-gram Model |
|
|
n2nmn.tensorflow
|
R. Hu, J. Andreas, M. Rohrbach, T. Darrell, K.
Saenko, Learning to Reason: End-to-End Module Networks
for Visual Question Answering. in ICCV, 2017. (PDF) |
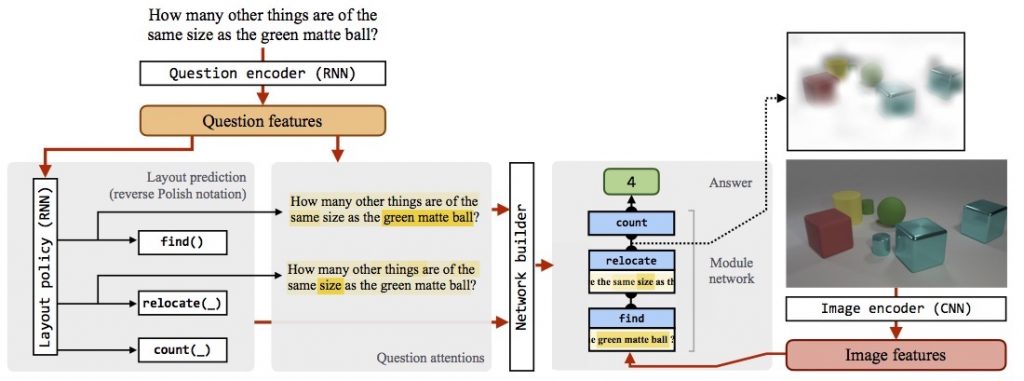 |
|
vqa-soft.pytorch
|
Accompanying code for "A Simple Loss Function for
Improving the Convergence and Accuracy of Visual Question
Answering Models" CVPR 2017 VQA workshop paper. |
|
|
video-to-text.torch
|
Video to text model based on NeuralTalk2 |
|
|
bottom-up-attention.caffe
|
Bottom-up attention model for image captioning and
VQA, based on Faster R-CNN and Visual Genome |
 |
|
ssta-captioning.pytorch
|
Repository for paper: Saliency-Based Spatio-Temporal
Attention for Video Captioning |
 |
|
caption-guided-saliency.Tensorflow
|
Supplementary material to "Top-down Visual Saliency
Guided by Captions" (CVPR 2017) |
 |
|
vqa.pytorch
|
Visual Question Answering in Pytorch |
 |