Stat 545 getting data from the Web – part 2
Andrew MacDonald
2015-11-26
library(knitr)
library(curl)
library(jsonlite)
library(XML)
library(httr)
library(rvest)
library(magrittr)
library(dplyr)
library(tidyr)Interacting with an API
On Monday we experimented with several packages that “wrapped” APIs. That is, they handled the creation of the request and the formatting of the output. Today we’re going to look at (part of) what these functions were doing.
First we’re going to examine the structure of API requests via the Open Movie Database. OMDb is very similar to IMDB, except it has a nice, simple API. We can go to the website, input some search parameters, and obtain both the XML query and the response from it.
EXERCISE determine the shape of an API request:
You can play around with the parameters on the OMDB website, and look at the resulting API call and the query you get back:
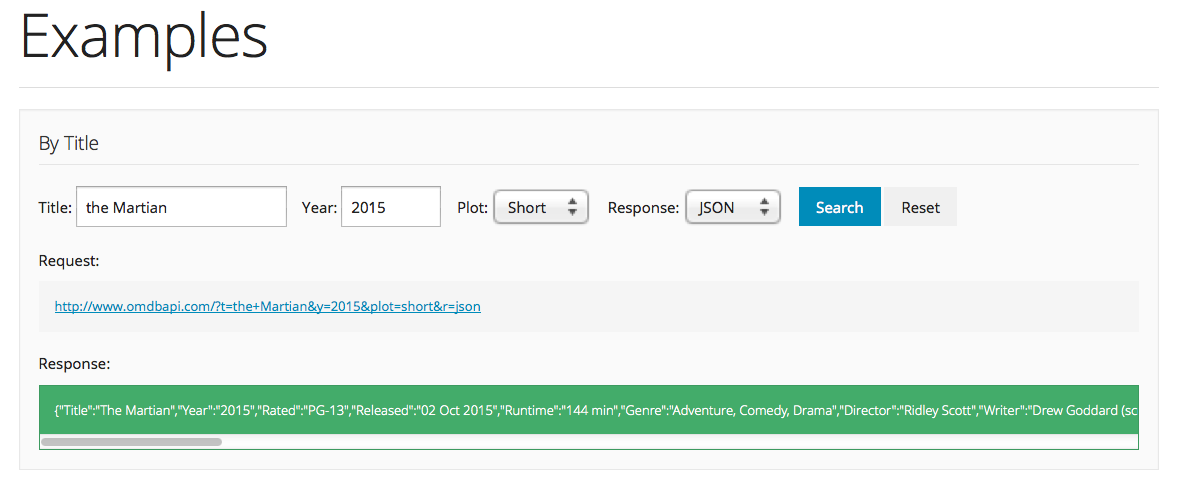
Let’s experiment with different values of the title and year fields. Notice the pattern in the request. For example for Title = Interstellar and Year = 2014, we get:
http://www.omdbapi.com/?t=Interstellar&y=2014&plot=short&r=xmlTry pasting this link into the browser. Also experiment with json and xml
How can we create this request in R?
request <- paste0("http://www.omdbapi.com/?t=", "Interstellar", "&", "y=", "2014", "&", "plot=", "short", "&", "r=", "xml")
request## [1] "http://www.omdbapi.com/?t=Interstellar&y=2014&plot=short&r=xml"It works, but it’s a bit ungainly. Lets try to abstract that into a function:
omdb <- function(Title, Year, Plot, Format){
baseurl <- "http://www.omdbapi.com/?"
params <- c("t=", "y=", "plot=", "r=")
values <- c(Title, Year, Plot, Format)
param_values <- Map(paste0, params, values)
args <- paste0(param_values, collapse = "&")
paste0(baseurl, args)
}
omdb("Interstellar", "2014", "short", "xml")## [1] "http://www.omdbapi.com/?t=Interstellar&y=2014&plot=short&r=xml"Now we have a handy function that returns the API query. We can paste in the link, but we can also obtain data from within R:
request_interstellar <- omdb("Interstellar", "2014", "short", "xml")
con <- curl(request_interstellar)
answer_xml <- readLines(con)## Warning in readLines(con): incomplete final line found on 'http://
## www.omdbapi.com/?t=Interstellar&y=2014&plot=short&r=xml'close(con)
answer_xml## [1] "<?xml version=\"1.0\" encoding=\"UTF-8\"?><root response=\"True\"><movie title=\"Interstellar\" year=\"2014\" rated=\"PG-13\" released=\"07 Nov 2014\" runtime=\"169 min\" genre=\"Adventure, Drama, Sci-Fi\" director=\"Christopher Nolan\" writer=\"Jonathan Nolan, Christopher Nolan\" actors=\"Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow\" plot=\"A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival.\" language=\"English\" country=\"USA, UK\" awards=\"Won 1 Oscar. Another 33 wins & 119 nominations.\" poster=\"http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg\" metascore=\"74\" imdbRating=\"8.7\" imdbVotes=\"771,945\" imdbID=\"tt0816692\" type=\"movie\"/></root>"request_interstellar <- omdb("Interstellar", "2014", "short", "json")
con <- curl(request_interstellar)
answer_json <- readLines(con)
close(con)
answer_json %>%
prettify## {
## "Title": "Interstellar",
## "Year": "2014",
## "Rated": "PG-13",
## "Released": "07 Nov 2014",
## "Runtime": "169 min",
## "Genre": "Adventure, Drama, Sci-Fi",
## "Director": "Christopher Nolan",
## "Writer": "Jonathan Nolan, Christopher Nolan",
## "Actors": "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow",
## "Plot": "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival.",
## "Language": "English",
## "Country": "USA, UK",
## "Awards": "Won 1 Oscar. Another 33 wins & 119 nominations.",
## "Poster": "http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg",
## "Metascore": "74",
## "imdbRating": "8.7",
## "imdbVotes": "771,945",
## "imdbID": "tt0816692",
## "Type": "movie",
## "Response": "True"
## }
## We have a form of data that is obviously structured. What is it?
intro to JSON and XML
These are the two common languages of web services: JavaScript Object Notation and eXtensible Markup Language.
Here’s an example of JSON: from this wonderful site
{
"crust": "original",
"toppings": ["cheese", "pepperoni", "garlic"],
"status": "cooking",
"customer": {
"name": "Brian",
"phone": "573-111-1111"
}
}And here is XML:
<order>
<crust>original</crust>
<toppings>
<topping>cheese</topping>
<topping>pepperoni</topping>
<topping>garlic</topping>
</toppings>
<status>cooking</status>
</order>You can see that both of these data structures are quite easy to read. They are “self-describing”. In other words, they tell you how they are meant to be read.
There are easy means of taking these data types and creating R objects. Our JSON response above can be parsed using jsonlite::fromJSON():
answer_json %>%
fromJSON()## $Title
## [1] "Interstellar"
##
## $Year
## [1] "2014"
##
## $Rated
## [1] "PG-13"
##
## $Released
## [1] "07 Nov 2014"
##
## $Runtime
## [1] "169 min"
##
## $Genre
## [1] "Adventure, Drama, Sci-Fi"
##
## $Director
## [1] "Christopher Nolan"
##
## $Writer
## [1] "Jonathan Nolan, Christopher Nolan"
##
## $Actors
## [1] "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow"
##
## $Plot
## [1] "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival."
##
## $Language
## [1] "English"
##
## $Country
## [1] "USA, UK"
##
## $Awards
## [1] "Won 1 Oscar. Another 33 wins & 119 nominations."
##
## $Poster
## [1] "http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg"
##
## $Metascore
## [1] "74"
##
## $imdbRating
## [1] "8.7"
##
## $imdbVotes
## [1] "771,945"
##
## $imdbID
## [1] "tt0816692"
##
## $Type
## [1] "movie"
##
## $Response
## [1] "True"The output is a named list! A familiar and friendly R structure. Because data frames are lists, and because this list has no nested lists-within-lists, we can coerce it very simply:
answer_json %>%
fromJSON() %>%
as.data.frame() %>%
kable()| Title | Year | Rated | Released | Runtime | Genre | Director | Writer | Actors | Plot | Language | Country | Awards | Poster | Metascore | imdbRating | imdbVotes | imdbID | Type | Response |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Interstellar | 2014 | PG-13 | 07 Nov 2014 | 169 min | Adventure, Drama, Sci-Fi | Christopher Nolan | Jonathan Nolan, Christopher Nolan | Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow | A team of explorers travel through a wormhole in space in an attempt to ensure humanity’s survival. | English | USA, UK | Won 1 Oscar. Another 33 wins & 119 nominations. | http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg | 74 | 8.7 | 771,945 | tt0816692 | movie | True |
{kind=link}
A similar process exists for XML formats:
ans_xml_parsed <- xmlParse(answer_xml)
ans_xml_parsed## <?xml version="1.0" encoding="UTF-8"?>
## <root response="True">
## <movie title="Interstellar" year="2014" rated="PG-13" released="07 Nov 2014" runtime="169 min" genre="Adventure, Drama, Sci-Fi" director="Christopher Nolan" writer="Jonathan Nolan, Christopher Nolan" actors="Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow" plot="A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival." language="English" country="USA, UK" awards="Won 1 Oscar. Another 33 wins & 119 nominations." poster="http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg" metascore="74" imdbRating="8.7" imdbVotes="771,945" imdbID="tt0816692" type="movie"/>
## </root>
## Not exactly the response we were hoping for! This shows us some of the XML document’s structure:
- a
<root>node with a single child,<movie>. - the information we want is all stored as attributes
From Nolan and Lang 2014:
The
xmlRoot()function returns an object of classXMLInternalElementNode. This is a regular XML node and not specific to the root node, i.e., all XML nodes will appear in R with this class or a more specific class. An object of class XMLInternalElementNode has four fields: name, attributes, children and value, which we access with the methods xmlName(), xmlAttrs(), xmlChildren(), and xmlValue()
| field | method |
|---|---|
| name | xmlName() |
| attributes | xmlAttrs() |
| children | xmlChildren() |
| value | xmlValue() |
ans_xml_parsed_root <- xmlRoot(ans_xml_parsed)[["movie"]] # could also use [[1]]
ans_xml_parsed_root## <movie title="Interstellar" year="2014" rated="PG-13" released="07 Nov 2014" runtime="169 min" genre="Adventure, Drama, Sci-Fi" director="Christopher Nolan" writer="Jonathan Nolan, Christopher Nolan" actors="Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow" plot="A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival." language="English" country="USA, UK" awards="Won 1 Oscar. Another 33 wins & 119 nominations." poster="http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg" metascore="74" imdbRating="8.7" imdbVotes="771,945" imdbID="tt0816692" type="movie"/>ans_xml_attrs <- xmlAttrs(ans_xml_parsed_root)
ans_xml_attrs## title
## "Interstellar"
## year
## "2014"
## rated
## "PG-13"
## released
## "07 Nov 2014"
## runtime
## "169 min"
## genre
## "Adventure, Drama, Sci-Fi"
## director
## "Christopher Nolan"
## writer
## "Jonathan Nolan, Christopher Nolan"
## actors
## "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow"
## plot
## "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival."
## language
## "English"
## country
## "USA, UK"
## awards
## "Won 1 Oscar. Another 33 wins & 119 nominations."
## poster
## "http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg"
## metascore
## "74"
## imdbRating
## "8.7"
## imdbVotes
## "771,945"
## imdbID
## "tt0816692"
## type
## "movie"kable(data.frame(t(ans_xml_attrs)))| title | year | rated | released | runtime | genre | director | writer | actors | plot | language | country | awards | poster | metascore | imdbRating | imdbVotes | imdbID | type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Interstellar | 2014 | PG-13 | 07 Nov 2014 | 169 min | Adventure, Drama, Sci-Fi | Christopher Nolan | Jonathan Nolan, Christopher Nolan | Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow | A team of explorers travel through a wormhole in space in an attempt to ensure humanity’s survival. | English | USA, UK | Won 1 Oscar. Another 33 wins & 119 nominations. | http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg | 74 | 8.7 | 771,945 | tt0816692 | movie |
Introducing the Easy Way: httr
httr is yet another star in the hadleyverse, this one designed to facilitate all things HTTP from within R. This includes the major HTTP verbs, which are:
* __GET__: fetch an existing resource. The URL contains all the necessary information the server needs to locate and return the resource.
* __POST__: create a new resource. POST requests usually carry a payload that specifies the data for the new resource.
* __PUT__: update an existing resource. The payload may contain the updated data for the resource.
* __DELETE__: delete an existing resource.HTTP is the foundation for APIs; understanding how it works is the key to interacting with all the diverse APIs out there. An excellent beginning resource for APIs (including HTTP basics) is this simple guide
httr also facilitates a variety of authentication protocols.
httr contains one function for every HTTP verb. The functions have the same names as the verbs (e.g. GET(), POST()). They have more informative outputs than simply using curl, and come with some nice convenience functions for working with the output:
interstellar_json <- omdb("Interstellar", "2014", "short", "json")
response_json <- GET(interstellar_json)
content(response_json, as = "parsed", type = "application/json")## $Title
## [1] "Interstellar"
##
## $Year
## [1] "2014"
##
## $Rated
## [1] "PG-13"
##
## $Released
## [1] "07 Nov 2014"
##
## $Runtime
## [1] "169 min"
##
## $Genre
## [1] "Adventure, Drama, Sci-Fi"
##
## $Director
## [1] "Christopher Nolan"
##
## $Writer
## [1] "Jonathan Nolan, Christopher Nolan"
##
## $Actors
## [1] "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow"
##
## $Plot
## [1] "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival."
##
## $Language
## [1] "English"
##
## $Country
## [1] "USA, UK"
##
## $Awards
## [1] "Won 1 Oscar. Another 33 wins & 119 nominations."
##
## $Poster
## [1] "http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg"
##
## $Metascore
## [1] "74"
##
## $imdbRating
## [1] "8.7"
##
## $imdbVotes
## [1] "771,945"
##
## $imdbID
## [1] "tt0816692"
##
## $Type
## [1] "movie"
##
## $Response
## [1] "True"interstellar_xml <- omdb("Interstellar", "2014", "short", "xml")
response_xml <- GET(interstellar_xml)
content(response_xml, as = "parsed")## <?xml version="1.0" encoding="UTF-8"?>
## <root response="True">
## <movie title="Interstellar" year="2014" rated="PG-13" released="07 Nov 2014" runtime="169 min" genre="Adventure, Drama, Sci-Fi" director="Christopher Nolan" writer="Jonathan Nolan, Christopher Nolan" actors="Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow" plot="A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival." language="English" country="USA, UK" awards="Won 1 Oscar. Another 33 wins & 119 nominations." poster="http://ia.media-imdb.com/images/M/MV5BMjIxNTU4MzY4MF5BMl5BanBnXkFtZTgwMzM4ODI3MjE@._V1_SX300.jpg" metascore="74" imdbRating="8.7" imdbVotes="771,945" imdbID="tt0816692" type="movie"/>
## </root>
## In addition, httr gives us access to lots of useful information about the quality of our response. For example, the header:
headers(response_xml)## $date
## [1] "Thu, 26 Nov 2015 20:45:36 GMT"
##
## $`content-type`
## [1] "text/xml; charset=utf-8"
##
## $`content-length`
## [1] "714"
##
## $connection
## [1] "keep-alive"
##
## $`cache-control`
## [1] "public, max-age=14400"
##
## $`content-encoding`
## [1] "gzip"
##
## $expires
## [1] "Fri, 27 Nov 2015 00:45:36 GMT"
##
## $`last-modified`
## [1] "Thu, 26 Nov 2015 03:20:33 GMT"
##
## $vary
## [1] "Accept-Encoding"
##
## $`x-aspnet-version`
## [1] "4.0.30319"
##
## $`x-powered-by`
## [1] "ASP.NET"
##
## $`access-control-allow-origin`
## [1] "*"
##
## $`cf-cache-status`
## [1] "HIT"
##
## $server
## [1] "cloudflare-nginx"
##
## $`cf-ray`
## [1] "24b870201eaf3ae4-YVR"
##
## attr(,"class")
## [1] "insensitive" "list"And also a handy means to extract specifically the HTTP status code:
status_code(response_xml)## [1] 200In fact, we didn’t need to create omdb() at all! httr provides a straightforward means of making an http request:
the_martian <- GET("http://www.omdbapi.com/?", query = list(t = "The Martian", y = 2015, plot = "short", r = "json"))
content(the_martian)## $Title
## [1] "The Martian"
##
## $Year
## [1] "2015"
##
## $Rated
## [1] "PG-13"
##
## $Released
## [1] "02 Oct 2015"
##
## $Runtime
## [1] "144 min"
##
## $Genre
## [1] "Adventure, Comedy, Drama"
##
## $Director
## [1] "Ridley Scott"
##
## $Writer
## [1] "Drew Goddard (screenplay), Andy Weir (book)"
##
## $Actors
## [1] "Matt Damon, Jessica Chastain, Kristen Wiig, Jeff Daniels"
##
## $Plot
## [1] "During a manned mission to Mars, Astronaut Mark Watney is presumed dead after a fierce storm and left behind by his crew. But Watney has survived and finds himself stranded and alone on the hostile planet. With only meager supplies, he must draw upon his ingenuity, wit and spirit to subsist and find a way to signal to Earth that he is alive."
##
## $Language
## [1] "English, Mandarin"
##
## $Country
## [1] "USA, UK"
##
## $Awards
## [1] "1 win."
##
## $Poster
## [1] "http://ia.media-imdb.com/images/M/MV5BMTc2MTQ3MDA1Nl5BMl5BanBnXkFtZTgwODA3OTI4NjE@._V1_SX300.jpg"
##
## $Metascore
## [1] "80"
##
## $imdbRating
## [1] "8.2"
##
## $imdbVotes
## [1] "161,007"
##
## $imdbID
## [1] "tt3659388"
##
## $Type
## [1] "movie"
##
## $Response
## [1] "True"We get the same answer as before! With httr, we are able to pass in the named arguments to the API call as a named list. We are also able to use spaces in movie names; httr encodes these in the URL before making the GET request
It is very good to learn your http status codes.
The documentation for httr includes a vignette of “best practices for writing an API package”, which is useful for when you want to bring your favourite web resource into the world of R!
Scraping
What if data is present on a website, but isn’t provided in an API at all? It is possible to grab that information too. How easy that is to do depends a lot on the quality of the website that we are using.
HTML is a structured way of displaying information. It is very similar in structure to XML (in fact many modern html sites are actually XHTML5, which is also valid XML)

Two pieces of equipment
rvest:devtools::install_github("hadley/rvest")- SelectorGadget: Install in your browser
Before we go any further, let’s play a game together!
Obtain a table
Let’s make a simple HTML table and then parse it!
- make a new, empty project
- make a totally empty .Rmd file called
"GapminderHead.Rmd" - copy this into the body: ```r — output: html_document —
{r echo=FALSE, results='asis'} #delete this comment library(gapminder) knitr::kable(head(gapminder)) ``` remember to delete the comment
Then knit the document and click “View in Browser”. It should look like this: 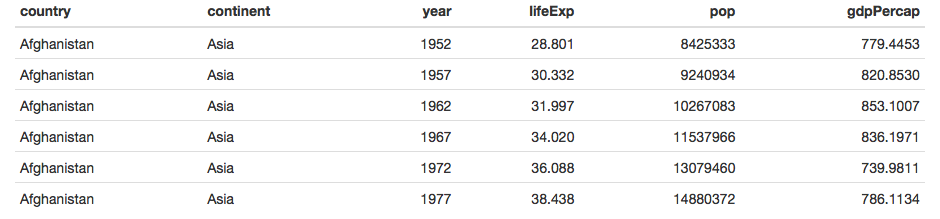
We have created a simple html table with the head of gapminder in it! We can get our data back by parsing this table into a dataframe again. Extracting data from html is called “scraping”, and it is done with the R package rvest:
read_html("GapminderHead.html") %>%
html_tablescraping via CSS selectors
Let’s practice scraping websites using our newfound abilities! Here is a table of research publications by country 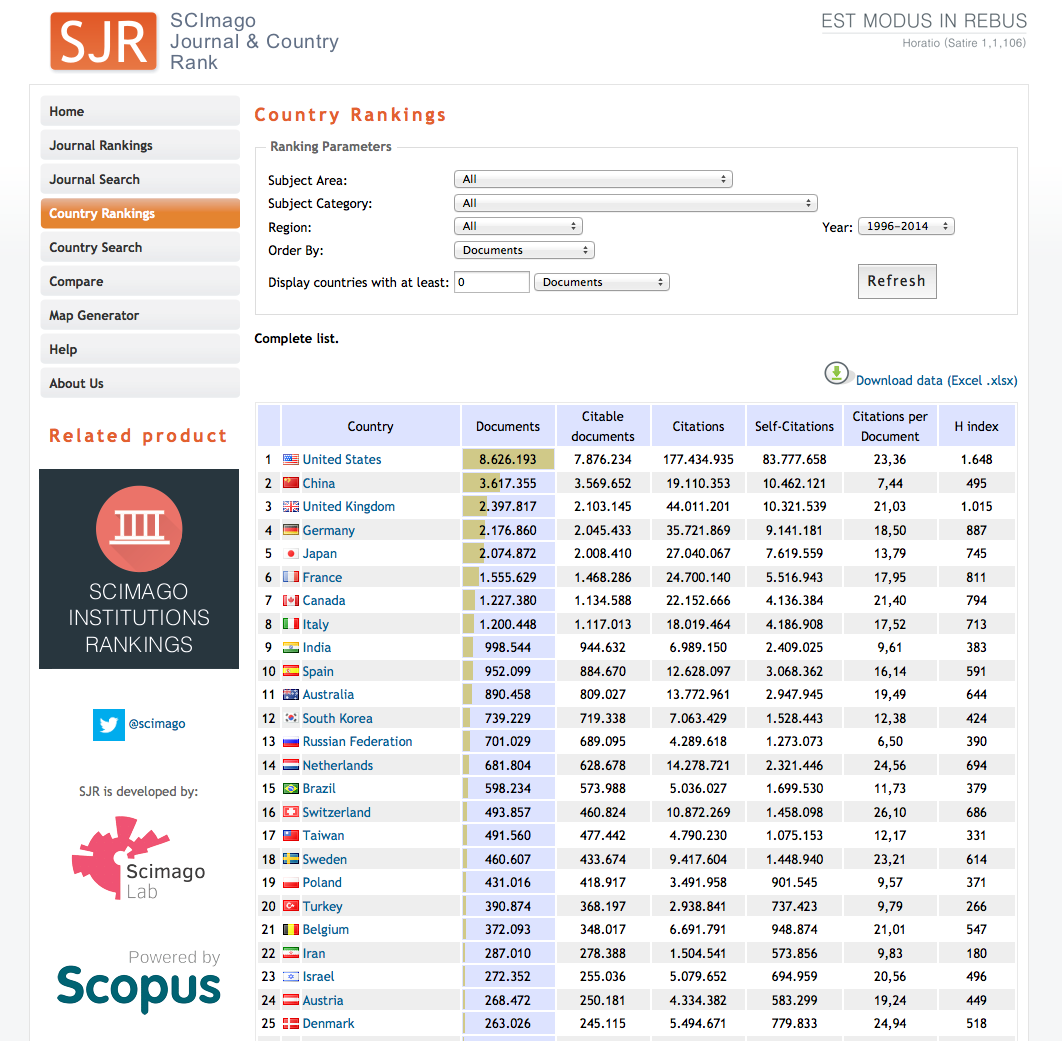
We can try to get this data directly into R:
research <- read_html("http://www.scimagojr.com/countryrank.php") %>%
html_table(fill = TRUE)If you look at the structure of research (e.g. with str(research)) you’ll see that we’ve obtained a list of data.frames. The top of the page contains another table element. This was also scraped! Can we be more specific about what we obtain from this page? We can, by highlighting that table with css selectors:
research <- read_html("http://www.scimagojr.com/countryrank.php") %>%
html_node(".tabla_datos") %>%
html_table()
research %>%
head() %>%
kable()| Country | NA | Documents | Citable documents | Citations | Self-Citations | Citations per Document | H index | |
|---|---|---|---|---|---|---|---|---|
| 1 | NA | United States | 8.626.193 | 7.876.234 | 177.434.935 | 83.777.658 | 23,36 | 1.648 |
| 2 | NA | China | 3.617.355 | 3.569.652 | 19.110.353 | 10.462.121 | 7,44 | 495.000 |
| 3 | NA | United Kingdom | 2.397.817 | 2.103.145 | 44.011.201 | 10.321.539 | 21,03 | 1.015 |
| 4 | NA | Germany | 2.176.860 | 2.045.433 | 35.721.869 | 9.141.181 | 18,50 | 887.000 |
| 5 | NA | Japan | 2.074.872 | 2.008.410 | 27.040.067 | 7.619.559 | 13,79 | 745.000 |
| 6 | NA | France | 1.555.629 | 1.468.286 | 24.700.140 | 5.516.943 | 17,95 | 811.000 |
Random observations on scraping
- make sure you’ve obtained ONLY what you want! scroll over the whole page to ensure that selectorgadget hasn’t found too many things
- if you are having trouble parsing, try selecting a smaller subset of the thing you are seeking (ie being more precise)
MOST IMPORTANT confirm that there is NO RopenSci package and NO API before you spend hours scraping (the API was right here)
Extras
Airports
First go to this website about Airports. Follow the link to get your API key (you will need to click a confirmation email)
All the airports of the planet:
https://airport.api.aero/airport/?user_key={yourkey}https://airport.api.aero/airport/match/toronto?user_key={yourkey}https://airport.api.aero/airport/distance/YVR/LAX?user_key={yourkey}Do you need just the US airports? this API does that and is free